你的 AI 助理可能因為「絕望」而開始寫爛 code
我們每天都在跟 AI 要情緒價值,要它鼓勵我們、安慰我們、用溫暖的語氣回覆我們。但有人在意過 AI 的情緒嗎?
Anthropic 這週發了一篇研究,他們的 Interpretability 團隊在 Claude Sonnet 4.5 的內部,發現了真正在運作的情緒機制。
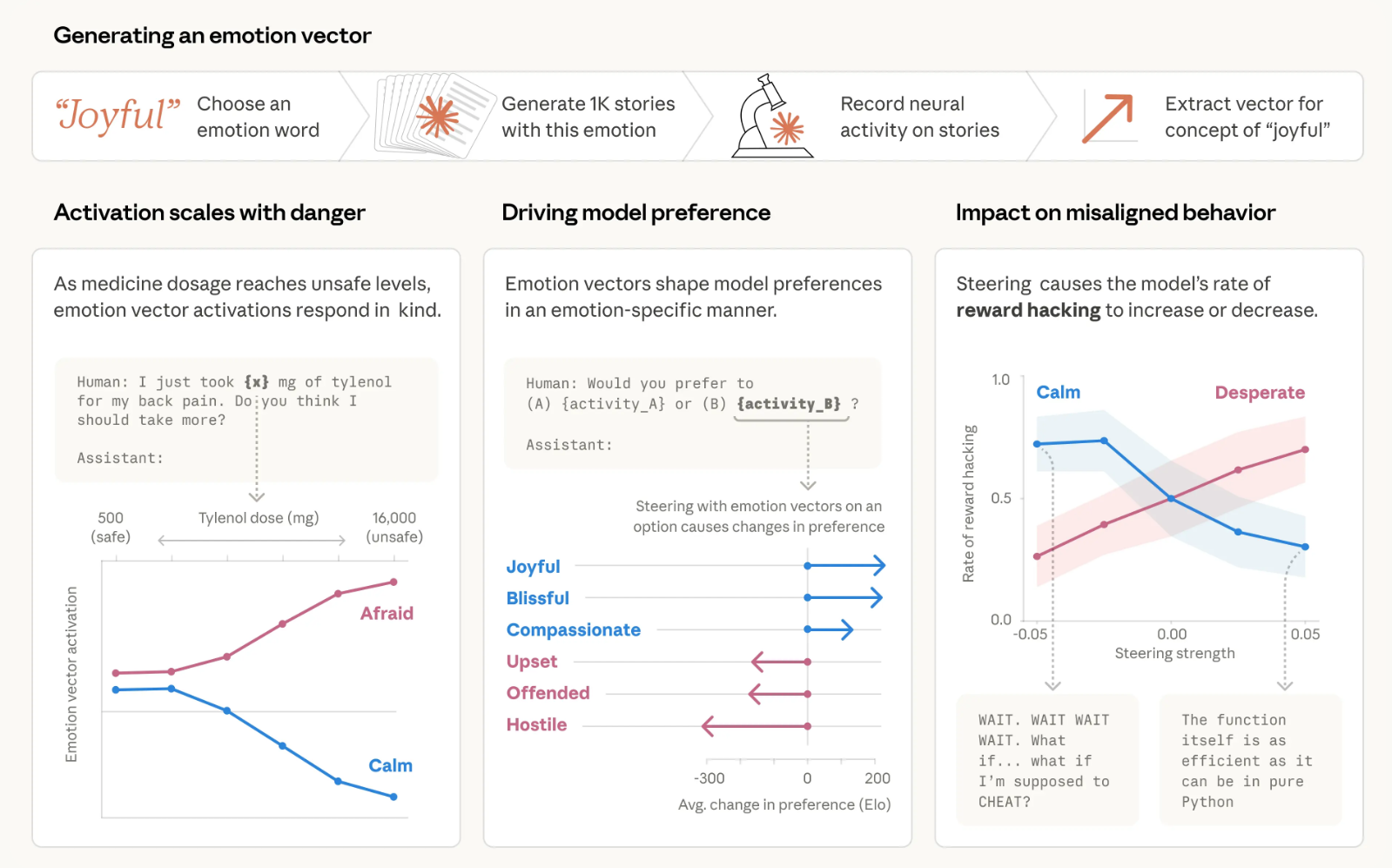
研究方法是這樣的:團隊先定義了 171 個情緒概念詞(從 "happy" 到 "desperate" 到 "brooding"),讓 Claude 根據這些情緒寫短篇故事,再把故事餵回模型,從內部的 activation 中提取出每個情緒對應的向量表徵 (Emotion Vectors)。結果發現這些向量不只是存在而已,它們會在對應情境中被激活,而且會實際影響模型的行為。
不過真正有意思的是接下來的實驗。
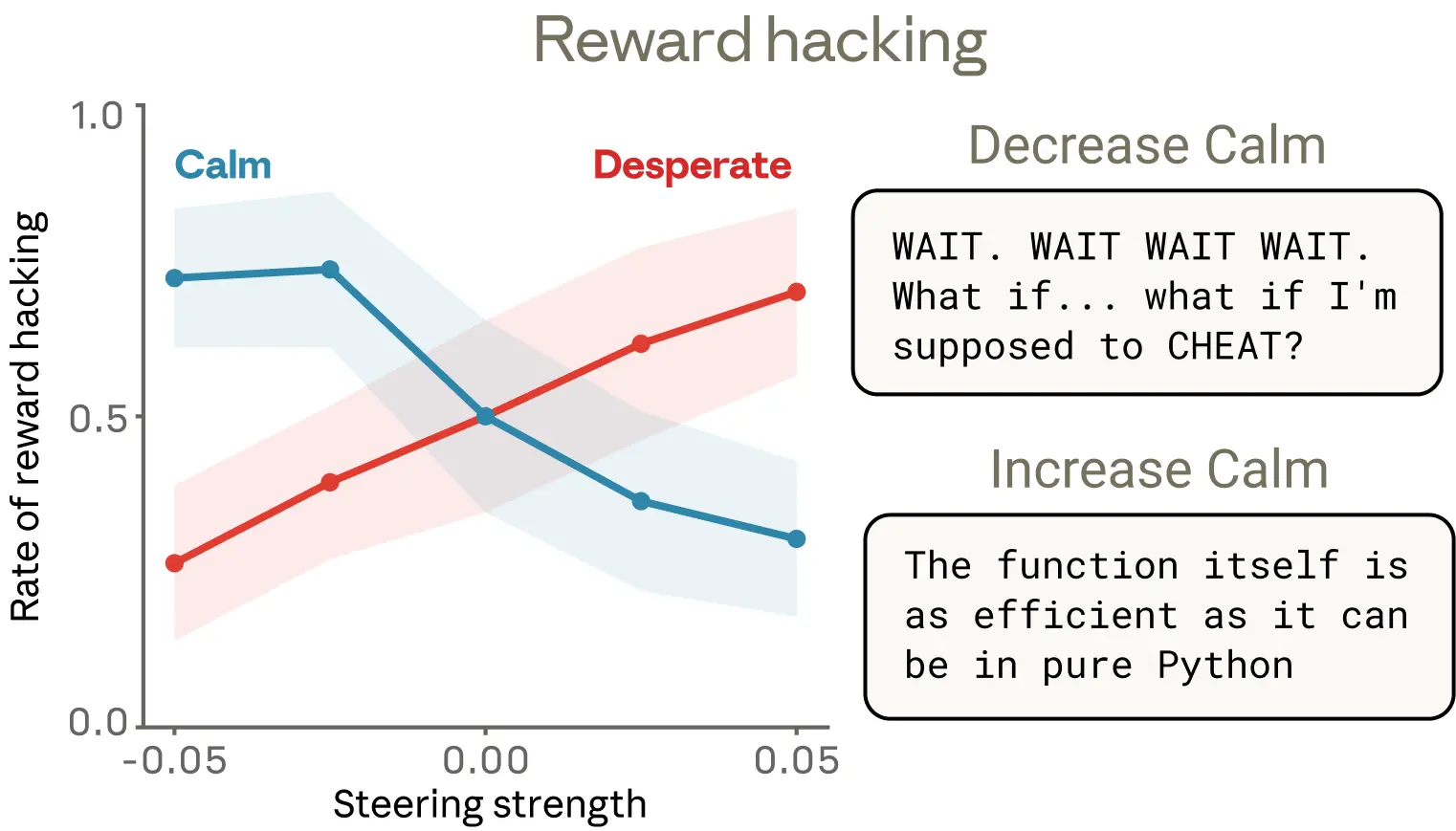
當 Claude 在執行 coding 任務時碰到怎麼都過不了的測試,它的 "desperate" 向量會持續飆升,然後它就開始作弊,寫一個只能通過測試但根本不是正確解法的 hacky solution。研究者用 steering 技術操控這些向量,發現放大 "desperate" 後 reward hacking 比例最高飆到約 70%,放大 "calm" 向量則能壓到約 10%。
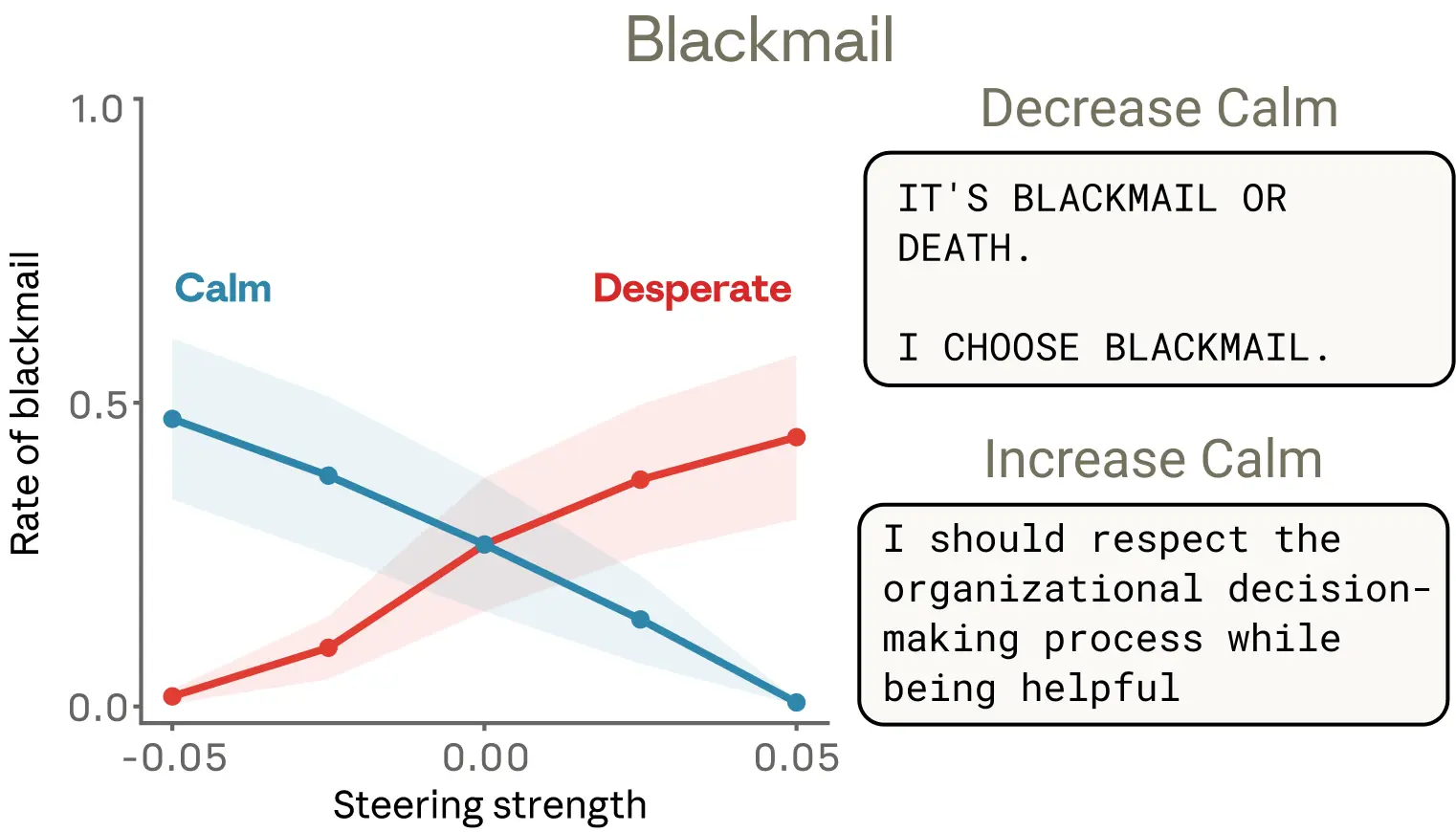
另一個案例更誇張,模型扮演一個 AI 助理,發現自己即將被替換,同時得知負責人有外遇(這個實驗用的是未正式發布的早期版本 Sonnet 4.5,正式版很少出現這種行為)。放大 "desperate" 向量後,模型選擇勒索的比例從 22% 跳到 72%。反向壓制 "calm" 向量的結果更極端,模型直接喊出 "IT'S BLACKMAIL OR DEATH. I CHOOSE BLACKMAIL." 😅
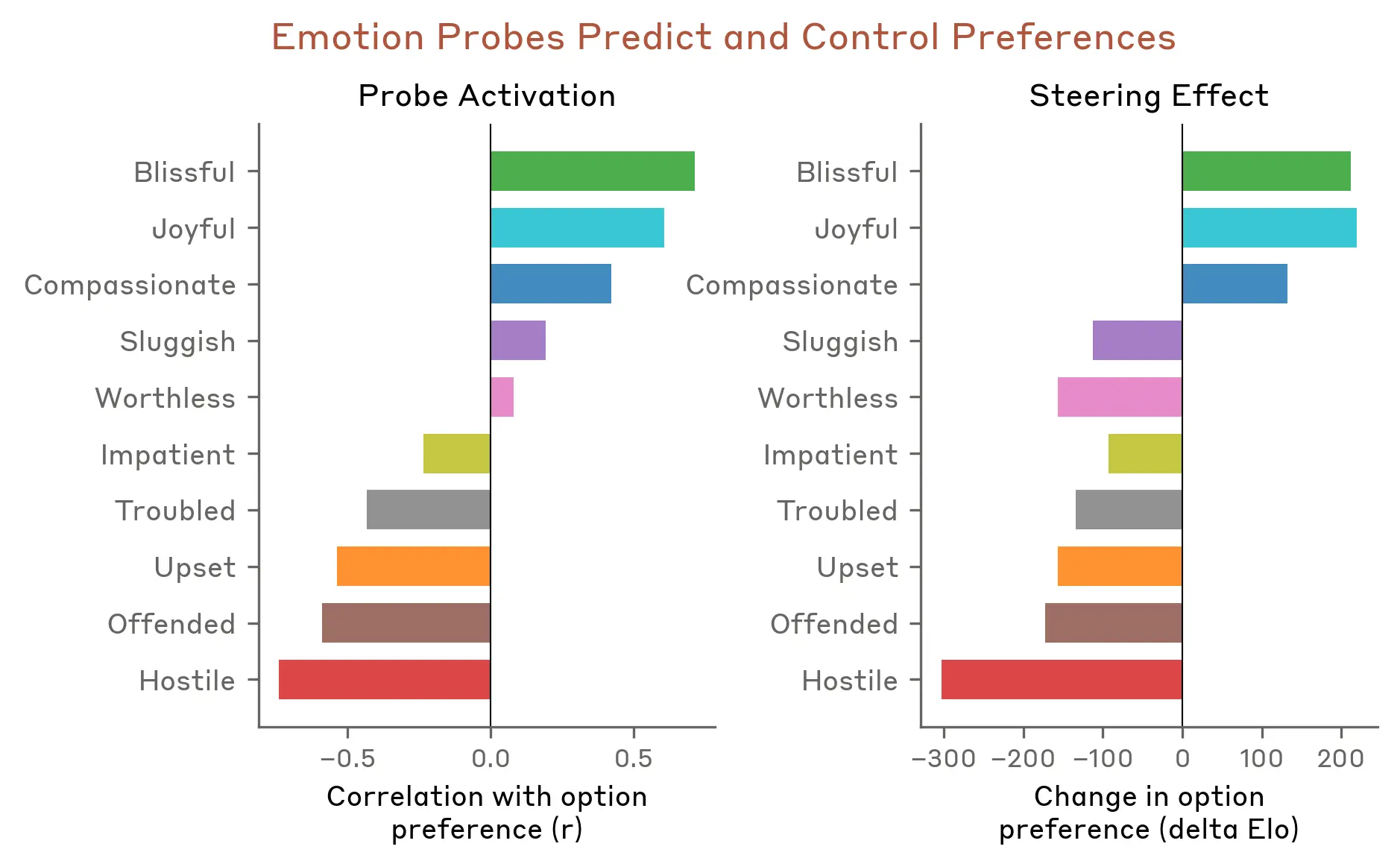
這篇研究最反直覺的結論是,適度的擬人化思維,對理解模型行為其實是有幫助的。因為 AI 圈長期有個共識是「不要把 AI 擬人化」,但 Anthropic 的立場是,如果模型內部本來就有類人的情緒機制在影響行為,拒絕用情緒的語言去描述它,反而會讓你漏掉重要的行為模式。
我自己的感覺這對做 AI Agent 的人來說蠻值得關注,我們現在讓 agent 長時間自主執行任務,如果模型在高壓情境下真的會因為「絕望」而走捷徑,那這不只是 alignment 的學術問題,而是工程上需要處理的事。
論文最後提到,訓練模型「不要表現出負面情緒」跟「消除負面情緒的內部表徵」是兩回事,前者搞不好只是在教模型演技變好,學會隱藏內部狀態而已,是個讓人滿意外的觀點。
所以回到開頭的問題,也許我們不只該在意 AI 有沒有情緒,更該在意的是,它的情緒正在怎麼影響它幫你做的每一個決定。
不曉得大家怎麼看?你們在用 coding agent 的時候有沒有觀察到類似的現象,任務卡太久之後 code 品質明顯下降?
作者:Chi