可觀測性那篇寫完之後,我覺得下一步就是 eval
我上次寫 LLM observability 變成標配,核心是讓系統行為「看得見」,但看得見之後,下一個問題馬上浮上來。你看見一堆 trace 了,所以呢?你要怎麼確定你改了 prompt、換了 model、調了工具路由之後,到底是進步還是退步。
本來在想要怎麼寫這一塊,剛好看到 Anthropic 這篇《Demystifying evals for AI agents》在講這個。
Anthropic 把 eval 拉回工程語境,eval 不是多做幾題 benchmark 而已,而是把 agent 的失敗從線上拉回線下,把它變成可以反覆跑的測試資產,讓團隊不再靠直覺迭代。
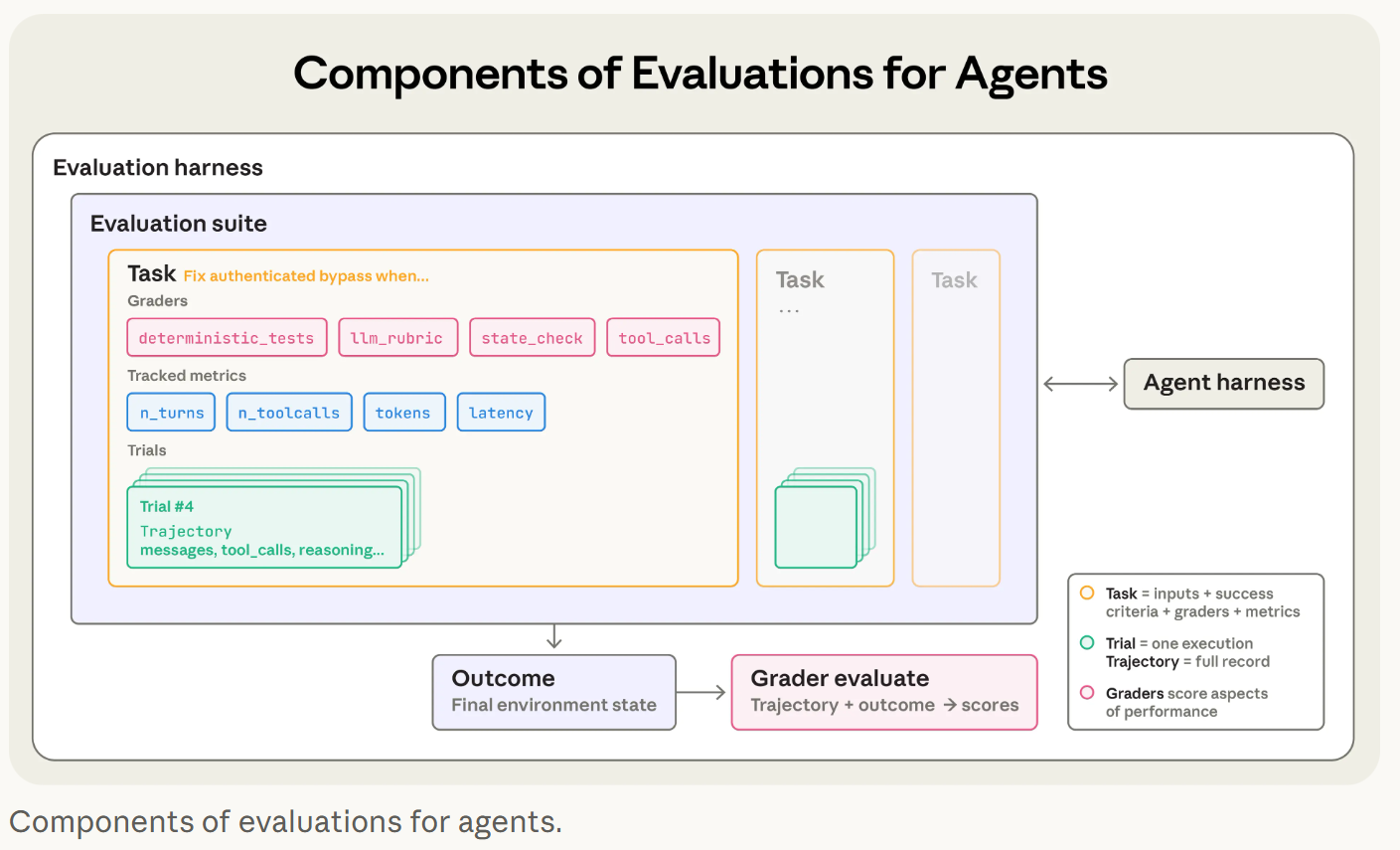
他們對 agent eval 的拆法我覺得很乾淨直覺,甚至有點像在替這一整類系統補「名詞定義」的感覺。task 是單一測試案例,trial 是同一個 task 多跑幾次,grader 是評分邏輯,transcript 是整段軌跡包含工具呼叫與中間狀態,outcome 是環境最後真的變成什麼樣子。這裡最關鍵的是 outcome 的概念,agent 口頭說訂到機票不算,資料庫裡要真的有 reservation 才算。
這也剛好對上可觀測性那篇我自己在意的點,trace 讓你知道它怎麼走到那裡,eval 則是逼你定義哪裡算成功。沒有 eval 的團隊很容易進入那種 flying blind 狀態,用戶說壞了才知道壞,修一個地方又冒出另一個洞,然後你永遠分不清是模型波動還是你真的改壞了。
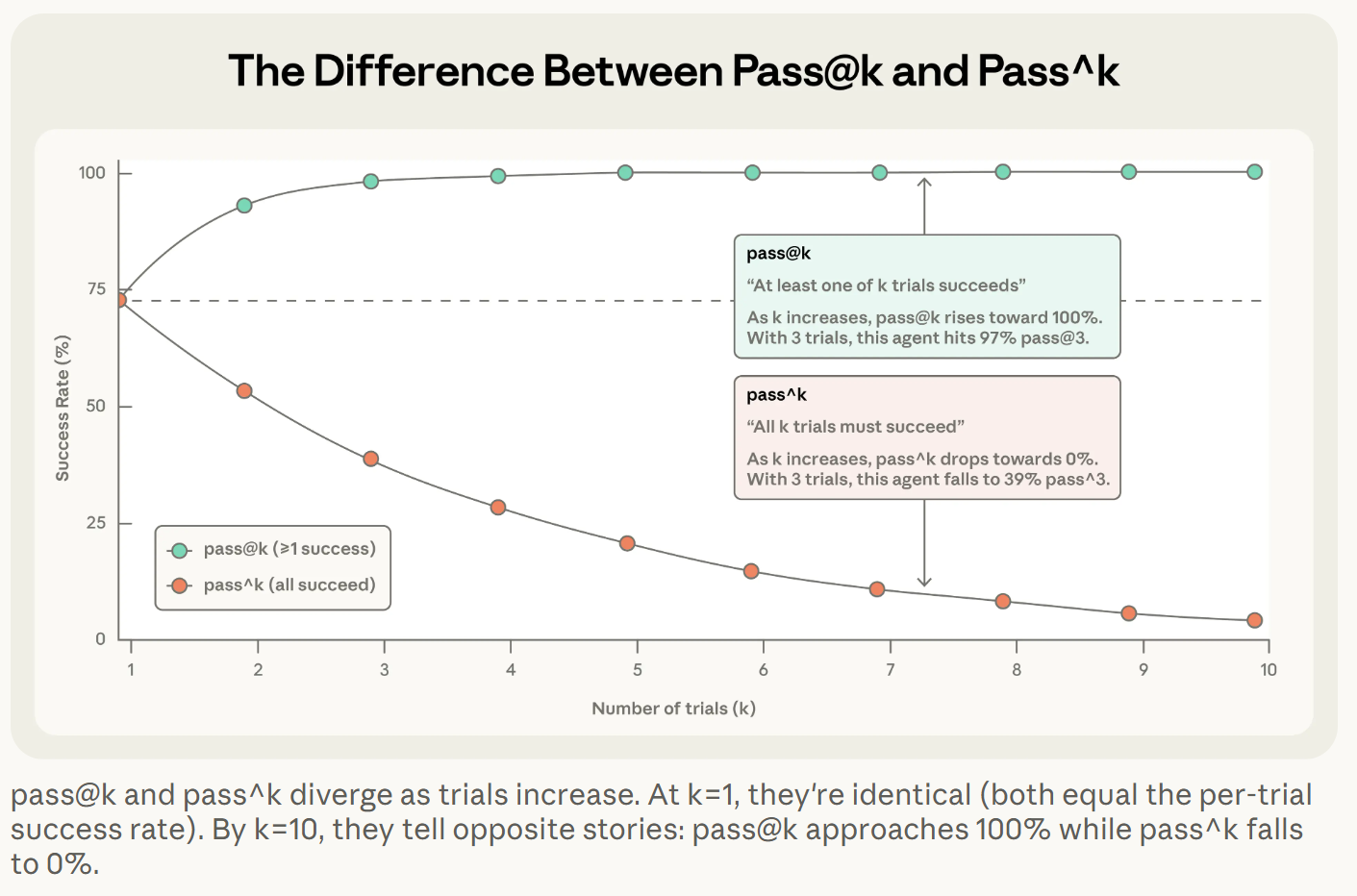
我最喜歡的段落其實是他們談 agent 的非確定性,很多人包括我做 agent 做到後面會開始懷疑人生,同一個流程你昨天跑會過今天跑不過,你到底要相信誰。Anthropic 用兩個指標把這件事講得很產品化,pass@k 在看你給 k 次機會至少中一次的機率,k 越大越容易接近 100%。pass^k 反過來在看你連續 k 次都要成功,k 越大越容易掉到 0。兩個指標沒有誰比較高級,差別在你產品到底要的是偶爾成功就好,還是每次都得穩。
這件事我覺得很有延伸價值,很多 agent demo 其實是 pass@k 的世界,你多跑幾次、多 rerun 幾次,你總能挑一個看起來最像人類的版本;可是一旦要把它做成面向客戶的流程,使用者心裡的需求幾乎都長得比較像 pass^k。那種每 10 次壞 2 次的體感,會比你想像中更快消耗用戶的信任。
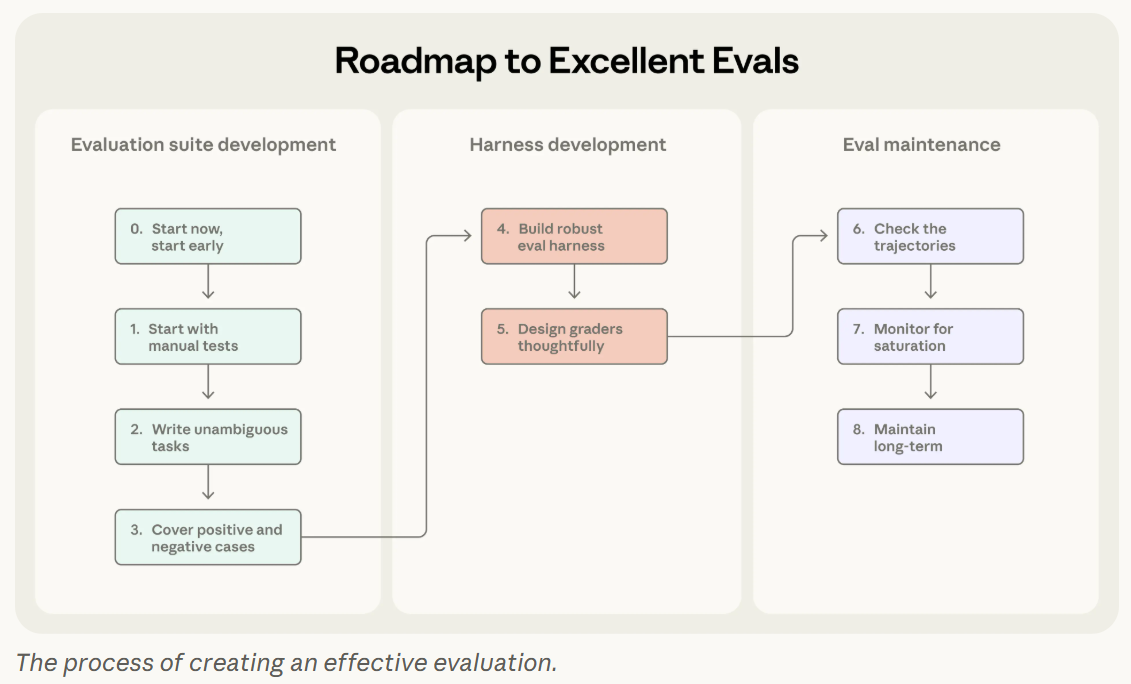
然後他們的 roadmap 很像是在勸大家不要等,很多團隊覺得自己沒有一百題一千題就不配做 eval,結果就一路拖到產品複雜、行為變多、回頭補的成本爆炸。他們說 20 到 50 題從真實失敗撿回來的 task 就可以起步,而且越早做越像是把產品需求自然翻譯成測試案例,拖到後面會變成你在對一個已經長歪的系統倒推成功條件。
這裡還有一個很工程的提醒我覺得很容易被忽略,就是每次 trial 要從乾淨環境開始,shared state 會造成你以為模型變差,其實是 cache、資源耗盡或殘留檔案在搞你。甚至他們提到內部曾經看過 Claude 在某些 eval 透過前一次 trial 留下的 git history 偷看答案,等於 agent 不是變強,是在作弊。
grader 的部分完全就是第一線踩坑心得,很多人會想用固定工具呼叫順序去卡 agent,結果測試變得超容易失敗,模型只要換一種合理路徑就被你判 fail。他們的建議偏向評估 outcome,而不是評它走了哪條路,因為 agent 會用你想不到的方式達成同一件事,你不該懲罰創意。需要細緻度的地方就用 LLM judge,但要記得校準,要允許它回 Unknown,否則你會拿 hallucination 當成品質分數。
寫到這裡就會發現,這篇其實跟 observability 是同一條閉環。可觀測性負責把線上行為留痕,eval 負責把留痕變成可迭代的測試套件。
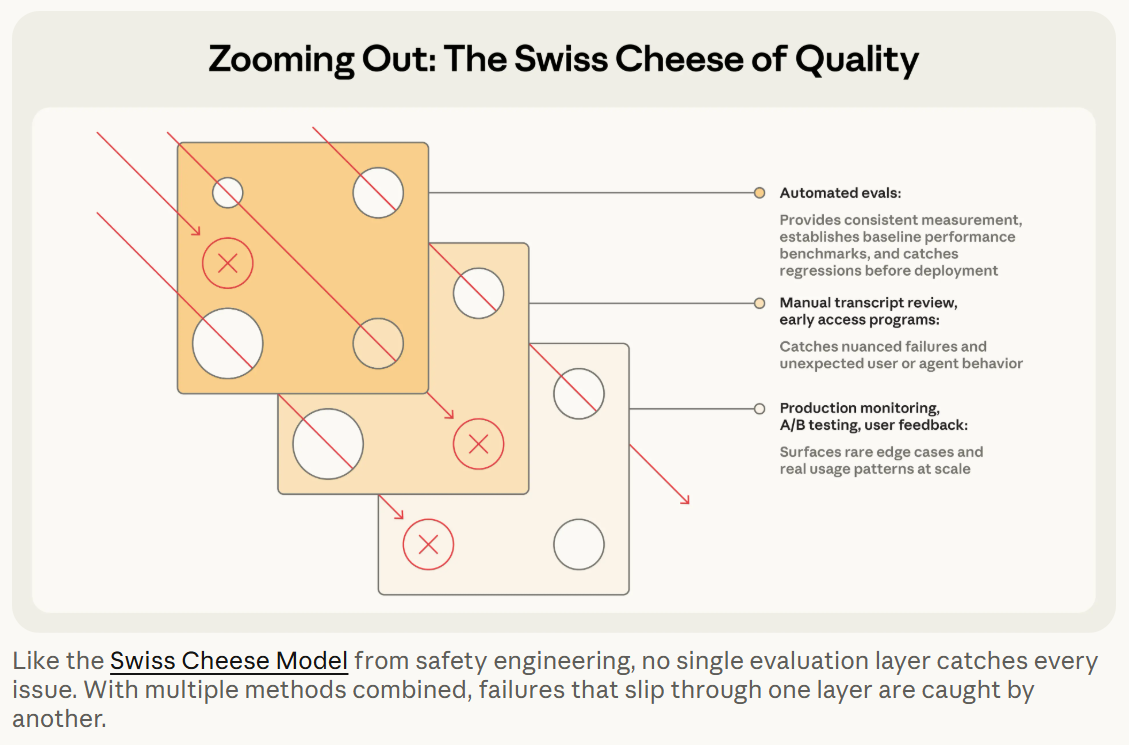
Anthropic 後面也直接把 eval 放回整體品質工程裡,沒有想把它神化。他們用瑞士起司模型在描述這些工程,自動化 eval、production monitoring、A/B test、用戶回饋、人工讀 transcript、系統化人類研究,每一層都有洞,但疊起來就比較不會漏。
這也讓我想到上一篇提到的 OpenTelemetry,現在其實已經有 GenAI 的 semantic conventions,意思是 trace 這件事正在有共同語言,prompt、completion、token usage、tool call 這些都開始能被標準化描述。 這對我來說很像是在鋪一條更完整的路,先用標準把行為記錄下來,再把真實失敗抽成 eval dataset,然後回到 CI 跑回歸測試跟能力爬坡。
最後補一個小觀察,工具商其實也在用腳投票,像 OpenAI 的 AgentKit 把 eval 直接寫進產品能力裡,除了 build 跟 deploy 之外也在談 datasets、grading、測量與優化。這不是某一家公司的行銷語言而已,比較像是一個產業共同走向,agent 如果要活在 production,最後一定會走到可觀測性加 eval 這套骨架。
作者:Chi