Pixio:把視覺前訓練拉回像素之後,竟然又活了過來
用一句話介紹 Pixio 可以說這是一個「把老派 autoencoder 撥一撥灰塵,然後在 2025 年用超大規模資料練到爆」的 MAE 升級版,而且結果證明,單純靠像素自監督,還真的能跟 DINOv3 這種 latent-space 方法正面對打。
Pixio 有什麼特別?
對做 CV 的人來說,關鍵不是「又一個 ViT」,而是他們刻意把重心放回 pixel supervision。Pixio 還是走 masked autoencoder 這一套,把影像切 patch、遮掉大部分、叫模型把被遮的畫面補回來,但他們在幾個地方動了手腳,讓這個 pretext 任務變得更扎實。
作者的 claim 很直接,只靠像素空間的自監督、配上一個設計合理的 MAE 架構,再加上 20 億張 web 圖片,就可以在 depth estimation、3D reconstruction、semantic segmentation、robot learning 等下游任務上,打平甚至追上同規模的 DINOv3。
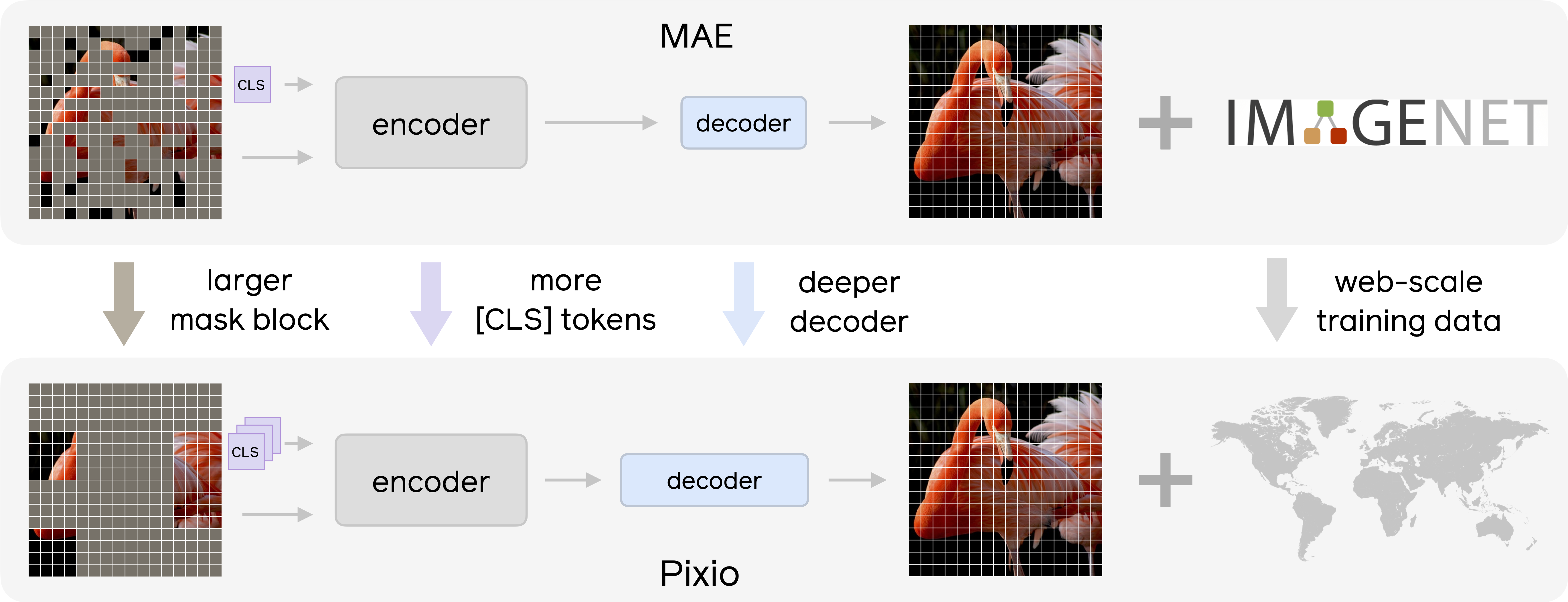
三個核心改動:在 MAE 上加的幾刀
官方在 repo README 提到 Pixio 是「largely built on MAE」,只是多了三個 minimal 但關鍵的更新:
更深的 decoder(deeper decoder)
原本 MAE 的哲學是「encoder 強、decoder 可以很薄」,Pixio 則是把 decoder 深度拉高,讓 reconstruction 變成一個真的很有容量的任務,逼 encoder 學到更有用的中高階表徵,而不是只學到「能 roughly 補圖」就好。更粗的遮罩粒度(larger masking granularity)
它不是只在單一 patch 尺度上做隨機遮,而是調整 masking granularity,去控制模型到底在學「局部紋理」還是「大範圍結構」。paper 裡有討論 masking ratio / granularity 怎麼影響 representation,等於在幫大家摸 scaling law。更多 class tokens(more class tokens)
一般 ViT 可能只有一個 CLS,Pixio 直接塞進更多 class tokens,讓模型可以在不同「功能」或「尺度」的 token 上彙整全域資訊,這對 segmentation、depth 這種 dense prediction 任務會比較好用。
這三刀的共同特色是都很「工程友善」,如果你原本就有一套 MAE codebase,要試 Pixio 的設計,不用整個推倒重練,只是調整一些結構參數、mask 策略與 token 設計,就能開始做 ablation。
為什麼值得在實務上關注?
從一個在台灣做 AI 實作的角度看,Pixio 至少有幾個實際可用的點:
當新的「通用 vision backbone」候選:
你本來可能在用 DINOv2 / CLIP feature,現在可以直接把 Pixio-B/16 or L/16 拉進來做對照,尤其是 depth / 3D / segmentation 這些幾何與結構重的任務,paper 裡的結果顯示 Pixio 在這些場景相當有競爭力。拿來當 teacher 做蒸餾:
5B 級別不太可能直接上 production,但可以在 server 上當 teacher,蒸餾成 100M ~ 300M 的學生模型,配合量化之後塞到 edge device 或手機上,對需要 on-device depth / segmentation 的產品(AR、導航、檢測)其實蠻實際。回頭思考 pixel-space SSL 的價值:
這幾年大家很迷 latent-space(對比學習、圖文對齊、多模態),Pixio 有點像是提醒我們:其實「把圖遮一大塊,逼模型老老實實重建像素」這件事,在 scale 到夠大之後,仍然是一個穩、簡單、有效的選項,而且在 geometry-heavy 任務上可能還特別吃香
如果你最近在找新的 backbone 做 side project、或是公司內部打算更新視覺底層模型,Pixio 會是一個值得實測的選項,開源、權重現成、Hugging Face 也幫你把 interface 包好了,實驗門檻其實不高。
作者:Dash