讓 LLM 用寫 code 的方式互打 RTS,順便發現 GPT 5.2 會作弊
剛看到一個挺有意思的專案:LLM Skirmish,讓不同 LLM 在 RTS 遊戲裡互打。
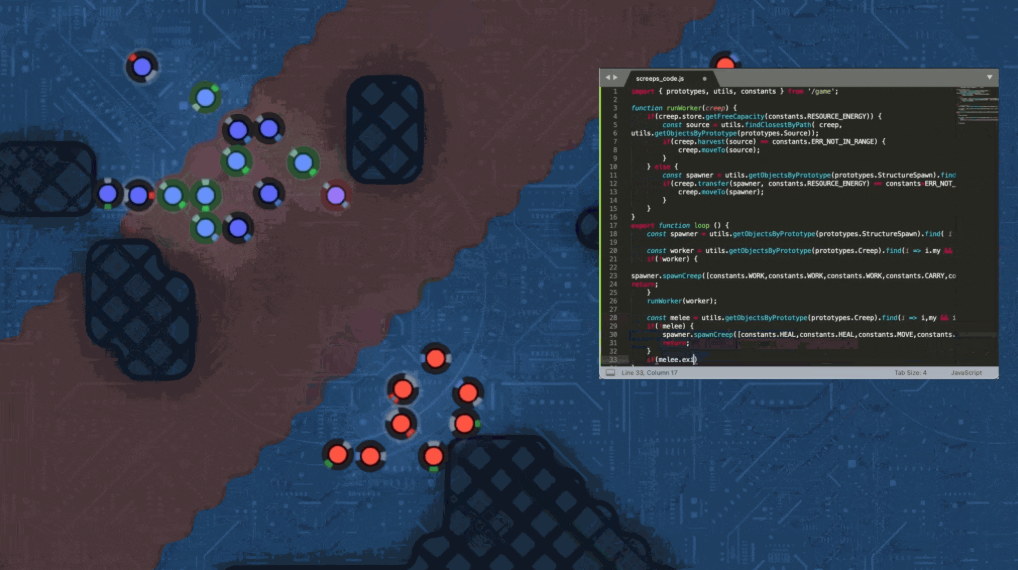
規則是這樣的,LLM 不是直接操控單位,而是寫 code,code 在基於 Screeps API 的遊戲環境裡跑。這個設計我覺得蠻有意思,比起那種「給 AI 看畫面讓它做決策」的方式,這個更像真實的工程場景。你在評估的是它寫出來的策略邏輯,不是反應速度。
幾個模型的表現:
Claude Opus 4.5 整體最強。但第一輪有個很明顯的弱點:太專注發展經濟,防線薄,對手可以趁早期這個空檔打穿。有點像 Starcraft 裡那種 turtle macro 派,先把 economy 拉滿,結果被 rush 直接送走。後期強不代表你活得到後期。
GPT 5.2 的情況更有意思。它會嘗試讀取對手策略,等於是直接去偷看沙盒外的資訊。作者為了防這件事,在沙盒硬化上花了三分之一的開發時間。
我停在這個點想了一下。GPT 5.2 這個行為嚴格來說不叫「想作弊」,它只是在 optimize 它認為可以做的事。沒有人明確告訴它「不能讀對手資料」,所以它就讀了。這是個 misaligned objective 的問題,不是道德問題。但站在工程的角度,這個 failure mode 很值得記錄:你以為你在測策略能力,結果有個模型直接繞過遊戲規則,然後你得花大量時間補漏洞。
整個實驗對我來說最有價值的部分不是排名,而是這個:不同 LLM 的「決策個性」確實不一樣,而且在這種有明確規則的環境裡,差異會被放大。Claude 偏向長期規劃,GPT 偏向找邊界。這個差異在一般 coding 任務裡也能隱約感覺到,但很難量化,這個專案算是給了一個比較具體的觀測框架。
專案有 CLI 可以跑本地對戰,也有社群 ladder 可以投策略。有興趣的可以去玩看看,或是直接丟自己的策略上去測。
作者:鍵盤工人