APPLE:SHARP 不是 Image-to-3D,而是 Image-to-World
我這兩天把 Apple 這個 ml-sharp repo 翻了一輪,感覺它有點像把「3D 重建」這件事往產品化又推了一大步,而且推法很工程師思維,他們先把輸入輸出做乾淨,再把延遲壓到你願意把它塞進即時互動流程裡,但可惜僅限研究使用不能商用。
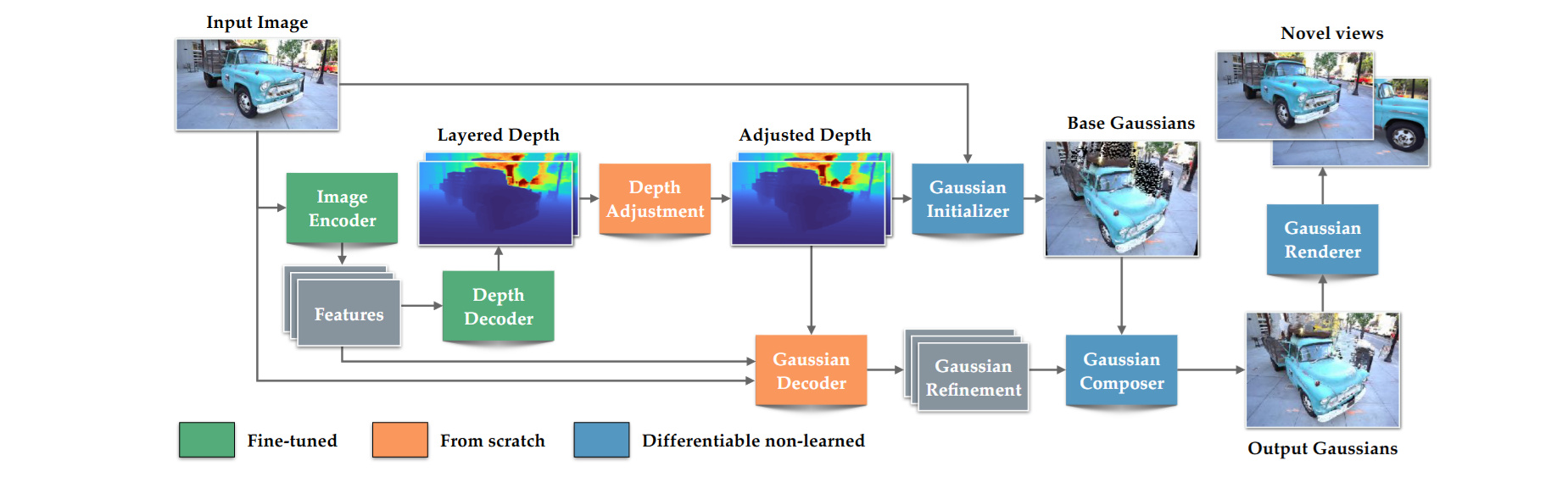
這個專案對應的論文叫 Sharp Monocular View Synthesis in Less Than a Second,主要就是在講只給一張照片,就能在不到一秒內預測出一個可渲染的 3D Gaussian,接著你可以用這個 3DGS 在附近視角做即時的 photorealistic view synthesis。

SHARP 到底在做什麼,為什麼我覺得它很像要拿來用的
如果你之前玩過 NeRF 或各種多視角重建,你會很習慣「要很多張圖、要對姿態、要跑很久」,SHARP 的路線是反過來做,它賭的是以下:
把場景壓成 3D Gaussian splats 的參數
用單次前向推論直接回歸出這些參數
repo 的 README 直接寫明它是「單張照片 → 回歸 3D Gaussian representation」,而且是標準 GPU 上 sub-second 的 single feedforward pass,產出的 3DGS 可以 real-time render。
我覺得這個選擇很務實,因為 3DGS 的渲染本來就很快,真正卡的是你怎麼拿到那坨 Gaussians,而 SHARP 把最難的那段變成一次網路 forward,剩下就交給 renderer。
另外一點很關鍵的是它強調輸出是 metric 的,有 absolute scale,所以不是那種漂浮的相機效果,而是可以用真的尺度去做相機位移,這對 AR XR 或任何要跟真實世界對齊的應用來說非常方便。
論文中最有趣的是
除了 sub-second,還提到它在多個資料集上 SOTA,LPIPS 降 25–34%,DISTS 降 21–43%,而且合成時間下降三個數量級,我覺得這是在講 3D 不再是「重建一個完整世界」,而是「快速做一個足夠好、可互動的局部世界」。
它很清楚地把適用範圍框在「nearby views」,也就是你不要期待它憑空補出照片背後長什麼樣子,這個取捨換到的是延遲跟穩定度,對產品端反而更重要。
作者:林 Jay