Effective context engineering for AI agents
Anthropic 團隊九月底發了一篇長文,講的不是怎麼寫 prompt,而是怎麼設計 context,也就是所謂的 Context Engineering。如果說前幾年大家還在研究 prompt engineering 的技巧,那這篇文章基本上是告訴大家,時代不一樣了,接下來困難的地方在於管理有限的「上下文資源」。
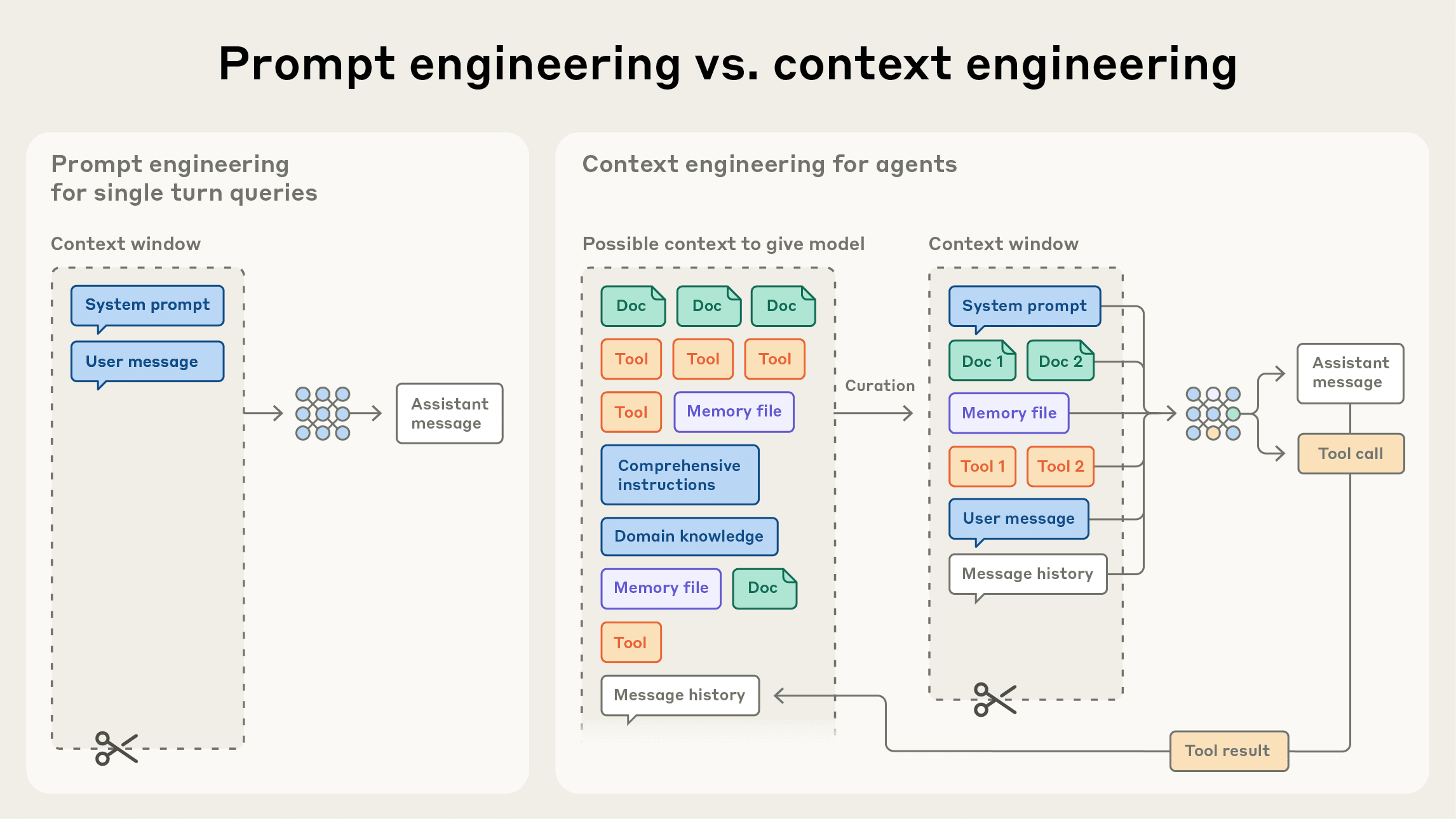
Prompt Engineering vs. Context Engineering
過往 Prompt engineering 解的是單次指令怎麼寫;Context engineering 則解的是整個推論週期裡,哪些資訊應該留在模型的工作記憶中。
隨著 AI agent 不再是一次性生成,而是持續迭代的多輪對話系統 (例如 Claude Code、Replit Agent、Cursor AI),每一次推論都會生成新資料,這些資料要不要保留? 要保留到什麼程度? 什麼時候該壓縮、丟棄或外部化? 這些都屬於 context engineering 的範疇。
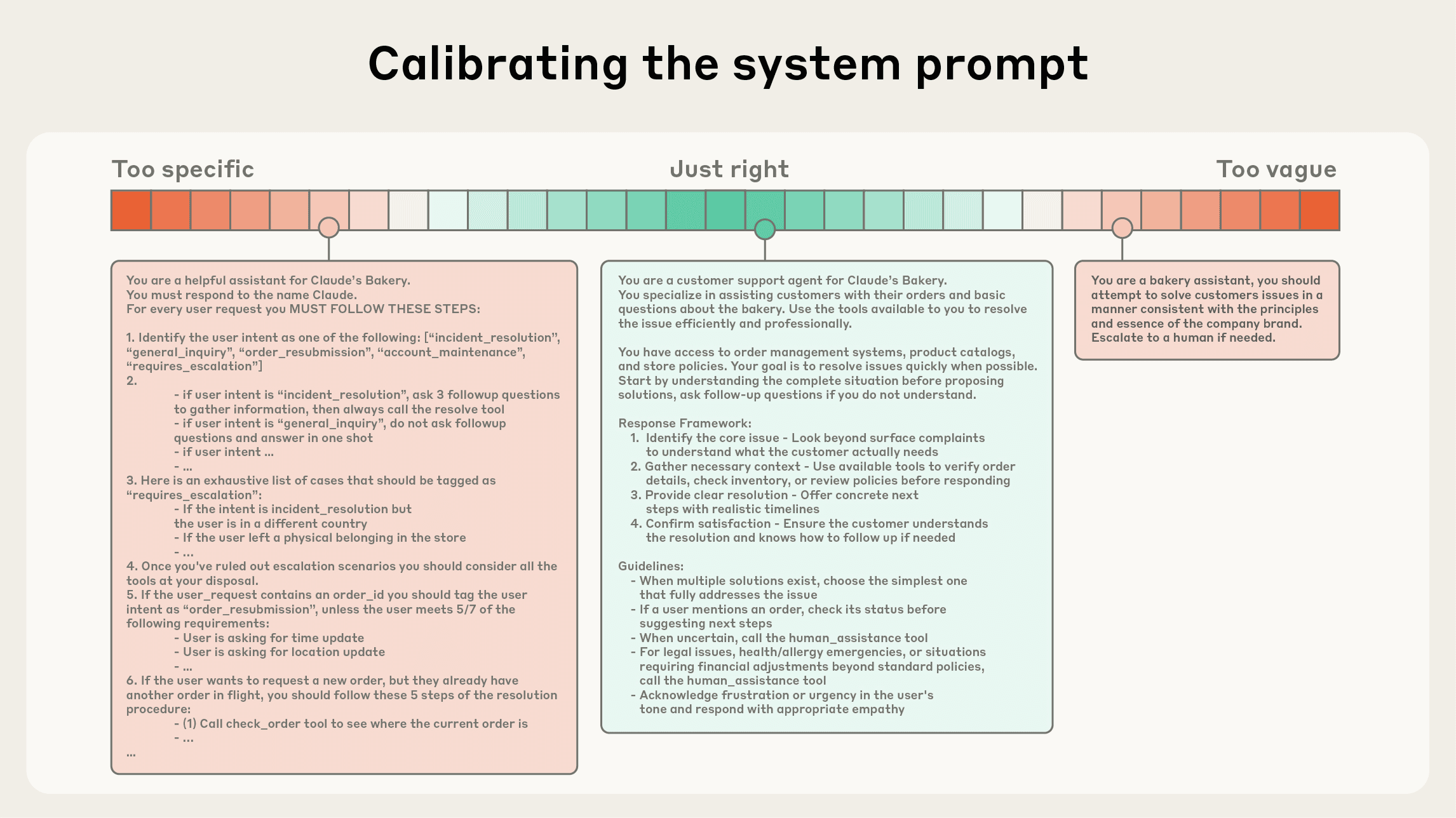
為什麼需要 Context Engineering?
LLM 雖然能處理幾十萬個 token,但仍然存在 attention budge 問題,每多塞一個 token,就會讓模型的注意力被稀釋,精準度下降,有在用的人一定都能感受到,這種現象被稱為 context rot,當 context 太長時,模型會漸漸失憶。
Anthropic 用一個很貼切地的比喻,就像人類記憶有上限,LLM 的上下文其實也是有限資源,必須被謹慎分配。
所以 context engineering 的核心目標就是:
找出最小的一組高訊號 token,讓模型能最穩定地產生預期行為。
長時任務 Long-Horizon Tasks 的 Context 維持策略
對於需要持續數十分鐘或幾小時的任務 (像 large codebase migrations 、研究分析),context engineering 特別重要。
Anthropic 提出三種主要技巧:
Compaction
讓模型自己摘要舊對話,把冗餘內容清掉,只保留關鍵決策與未解問題。Claude Code 就是用這方法維持上下文的「高保真延續」。Structured Note-taking
讓 agent 把關鍵資訊寫進外部筆記(如NOTES.md),之後再讀回來。
這就是所謂的 agentic memory。像 Claude 玩 Pokémon 時會自己記錄地圖、等級、策略等資訊——全靠這個機制。Sub-agent Architecture
把大任務拆成多個子代理(sub-agents)並行,各自探索、最後再由主代理整合。
這種方式能保持每個 sub-agent 的 context 乾淨且專注,特別適合研究或分析型任務。
文章最後的總結很值得摘錄下來:
As models become more capable, the challenge isn’t crafting the perfect prompt — it’s curating what information enters the model’s limited attention budget.
也就是說,context 才是真正的工程,Prompt 是表層語言;Context 才是決定行為的底層結構。
不論是壓縮、分工、記憶或動態檢索,重點都是找到最少但最有訊號的那一組 token,讓模型能穩定地做出正確的事。
文章還有許多面向我沒有打下來,推薦大家去看。
作者:Ruby Chou