研究流程也能用 Diffusion 思維? Google 提出的 TTD-DR
最近看到 Google Cloud 提出一個新 framework,叫 TTD-DR (Test-Time Diffusion Deep Researcher),覺得蠻有意思的,它的想法其實很貼近我們平常寫 paper 的習慣:第一版一定是草稿亂七八糟,缺 citation、邏輯鬆散,甚至還會有錯誤,接下來就會一邊補文獻、一邊修段落,慢慢把雜訊清掉,最後才會收斂成一篇正式的文章。
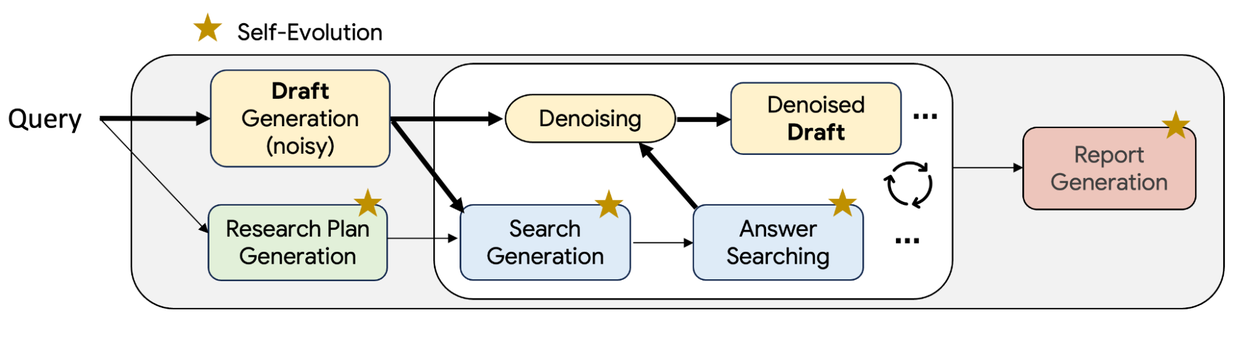
TTD-DR 就是把這個過程形式化成一個「擴散」的過程,初稿被視為 noisy sample,每一次檢索與修稿就是 denoising step,一輪一輪把雜訊抹掉。最後的定稿不只是靠單次檢索,而是靠這種持續迭代才慢慢變乾淨。
技術上有兩個點我覺得蠻新鮮的:
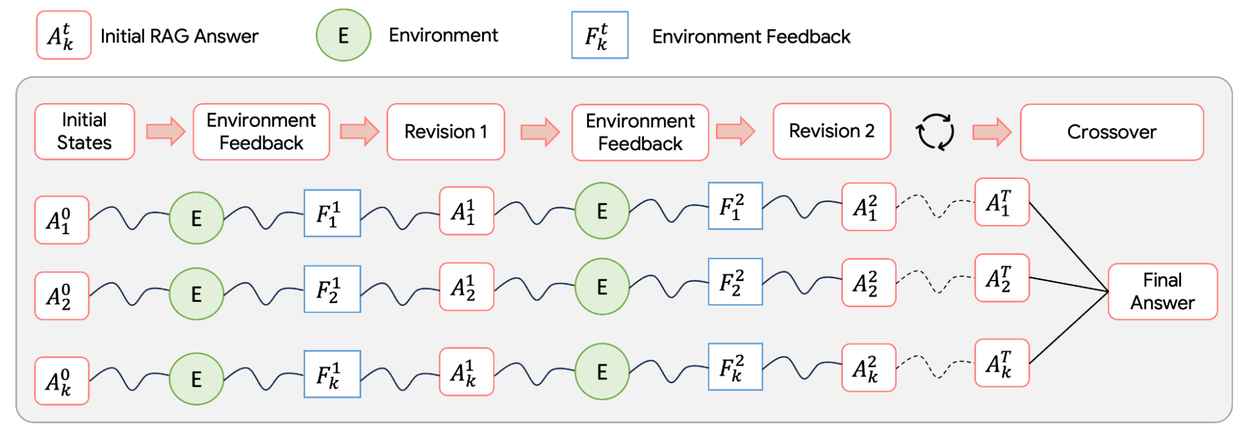
component-wise self-evolution:每個步驟不是只生成一個答案,而是生成多個變體,然後用 LLM-as-a-judge 打分,還會給 textual feedback,接著再修正。最後把不同版本融合成一個品質更好的答案。
report-level denoising with retrieval:報告草稿會被丟回去生成下一輪檢索問題,拿到新資訊後再修稿。這樣 draft 就像真的在「演化」,不斷補齊缺的東西。
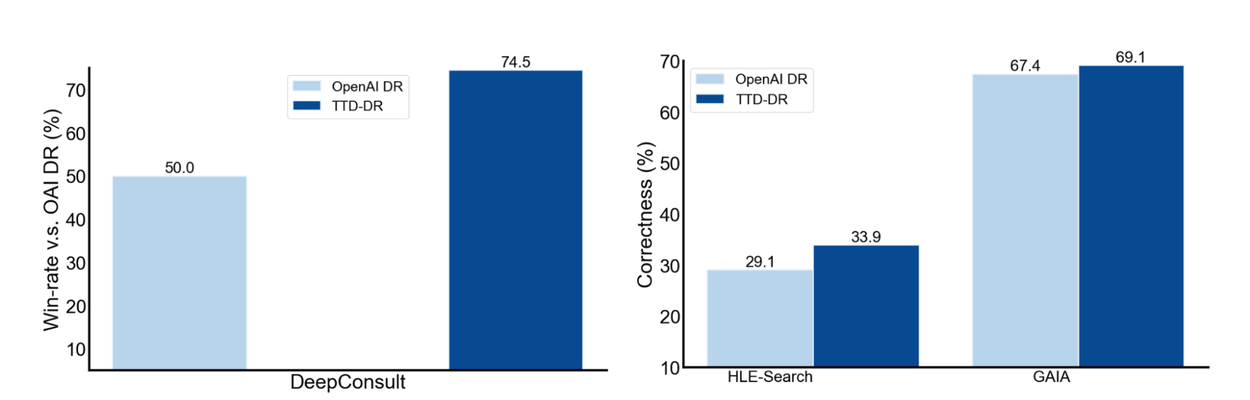
實驗結果還蠻亮眼的。在長篇研究報告任務(DeepConsult)上,對比 OpenAI Deep Research,TTD-DR 有 74.5% 的勝率;在 multi-hop reasoning 的資料集(HLE、GAIA)上也都有幾個 % 的提升。更有趣的是 ablation study:如果只有 backbone,其實輸 OpenAI;但加上自我進化後就開始反超,再加上 diffusion with retrieval 整個就全面領先。
我自己覺得亮點不只是 benchmark 上贏了,而是這個 framing 本身很自然。很多 RAG 系統卡在「一次檢索要很準」,導致上下文容易散掉;但如果把草稿當作 anchor,整個流程就會有 focus,也比較像人類真的在做研究。某種程度上,這可能比單純 chain-of-thought 或多答案 voting 更符合實際需求。
不知道大家怎麼看這種草稿導向的設計? 會不會未來的 DR agent 都會朝這個方向走
作者:Jacky