A Frontier Open-Source Text-to-Speech Model
微軟幾天前發布了新的開源 TTS 技術 VibeVoice,旨在解決傳統 TTS 會面臨的以下問題:
長文本不穩定:遇到較長的對話容易不穩、且情感缺失。
多人說話限制:多數模型僅支援 1-2 位說話者,難應對Podcast、劇本等複雜場景。
語音一致性不足:同一角色不同段落的聲音風格難以保持統一。
互動與轉場生硬:自然對話、情感流動及音效插入仍不成熟。
官方說可製作長達 90 分鐘、最多 4 位說話者 的連續語音,還滿令人期待的,這樣之後就可以文字稿的方式,生成一整集 Podcast 或有多角色的有聲小說,還不需人工剪接。比以前在實作上要拼接多段 TTS 的輸出,且一致性難控來說方便很多。
VibeVoice 有 7B 跟 1.5B 的,附上一些連結,1.5B 的可以去 Colab 試試
7B 在 Realism、Richness、Preference 三個指標上都領先 Google Gemini 2.5、ElevenLabs V3,1.5B 的表現其實也不算差。
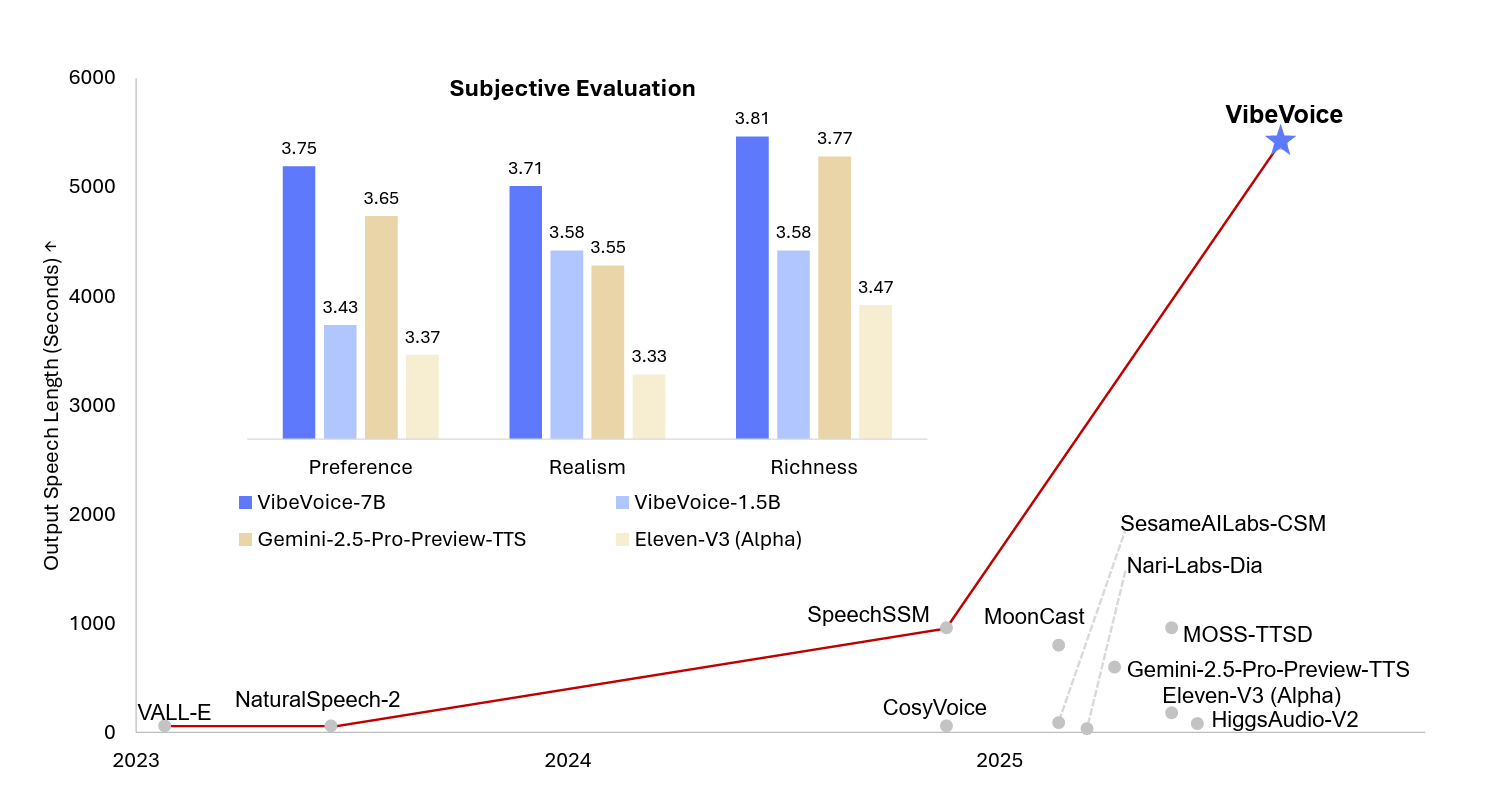
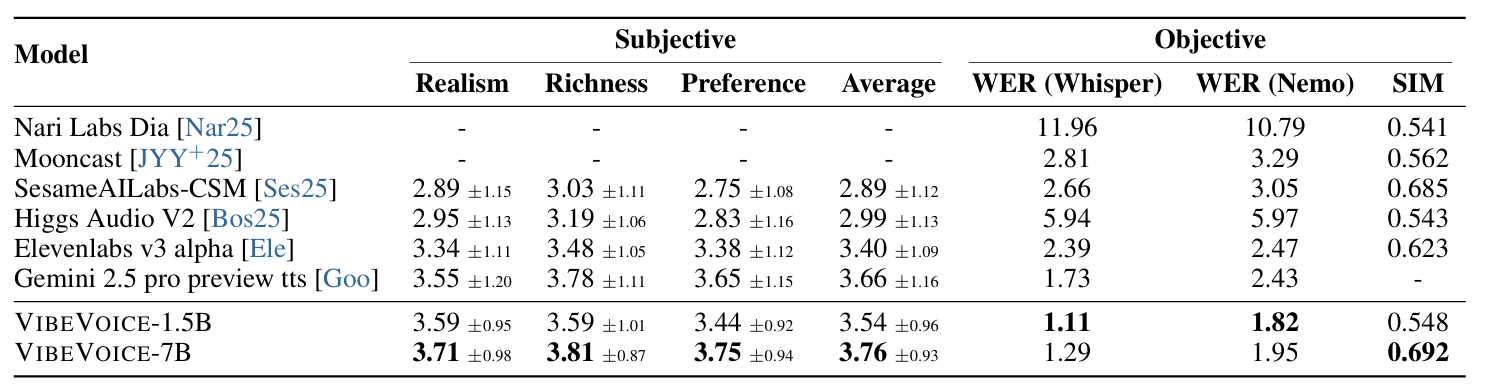
WER 也最低可以到 1.11,滿令人驚豔的;SIM 也明顯比大多開源模型更接近原始 speaker 的音色特徵。
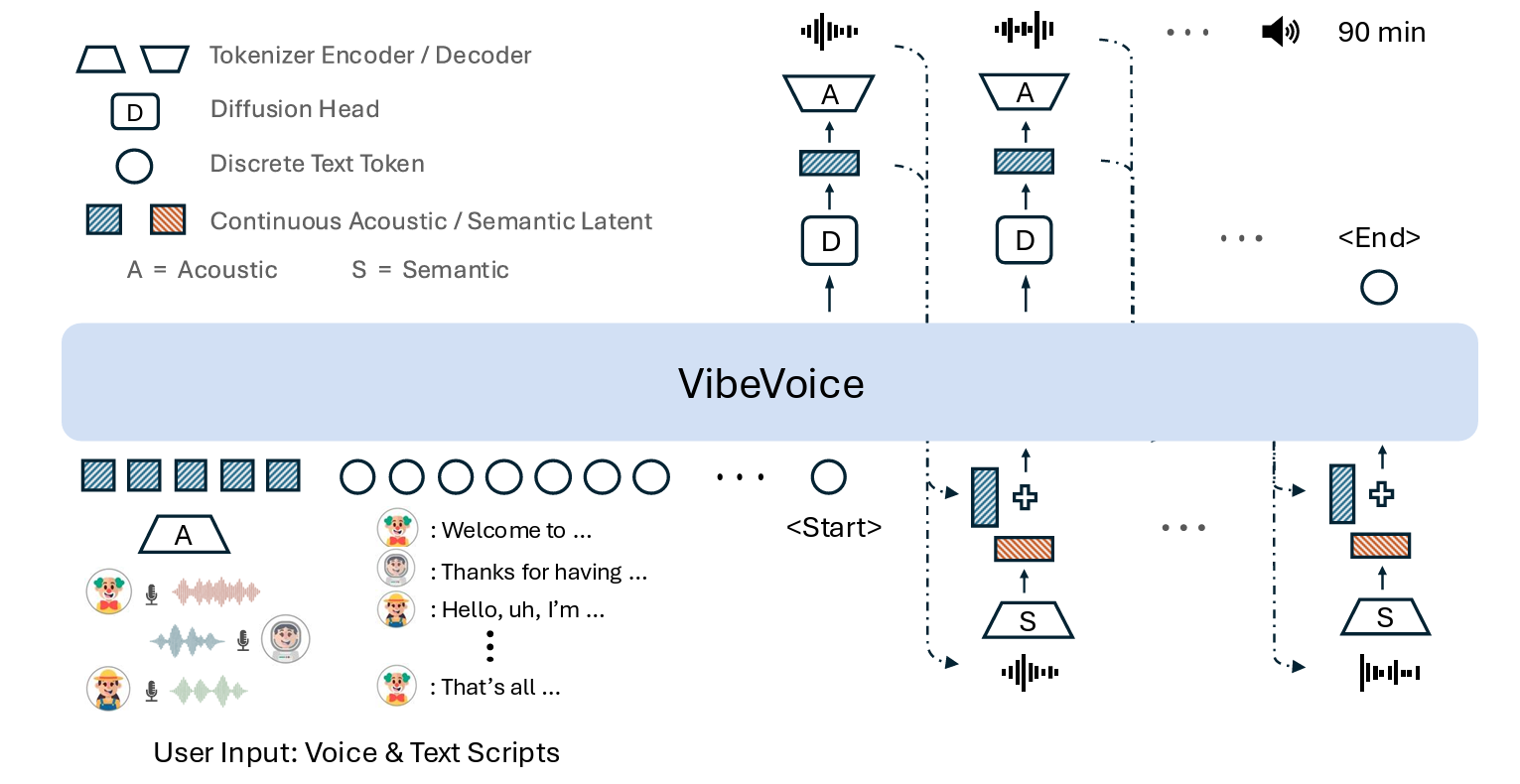
另外覺得他們的架構設計蠻有意思的,簡單整理幾個地方:
Next-Token Diffusion:他們不是一次生成整段語音,而是 token-by-token 的方式,每個 token 都透過 diffusion 去降噪,結合 LLM 的能力(這邊都用),讓 90 分鐘的對話都能保持自然連貫。
Acoustic + Semantic Tokenizer:聲音可以被壓縮到超低 7.5 Hz 的 frame rate,3200x 壓縮但音質還能維持,而且語音內容和音質是分開建模的,避免長時間生成時內容漂移或聲音變形。
LLM + Diffusion Head:整個 pipeline 很直觀:文字 + speaker embedding 餵進 LLM,LLM 理解上下文後,Diffusion Head 再把對應的語音特徵生成出來,最後 decoder 還原成音訊
Scalability:1.5B 到 7B 的 scaling 很明顯,模型變大後語音的自然度、豐富度都提升不少,說明架構本身很適合隨算力進化,不過我還沒實際測試差異。
VibeVoice 目前僅限研究用途,不過可預期未來出現很多 AI 成的 Podcast、自動廣播、有聲書等等,且 Deepfake 的問題應該還是一大爭議
另外雖然 VibeVoice 主要使用中、英文語料訓練,但不知道中文表現如何,晚點測試
作者:Chi