不同語言在不同模型的Tokenizer上的 token 數計算
之前有 PO 過一篇文章,討論文言文、繁體中文、簡體中文與英文在 Token 數量上的差異。最近剛好看到一位研究員 Aran Komatsuzaki,他在 Twitter(X)上個月底也提到了類似的事情。
他找了所有模型的 Tokenizer,針對不同語言進行大規模的比較,並得到一張很重要的 Heatmap。
他的實驗方式如下:
1. 選取 AI 領域中非常重要的論文《The Bitter Lesson》。
2. 將該論文轉換成 9 種語言。
3. 分別使用 6 種不同的 Tokenizer 計算 Token 數。
4. 最後彙整成一張 Heatmap。
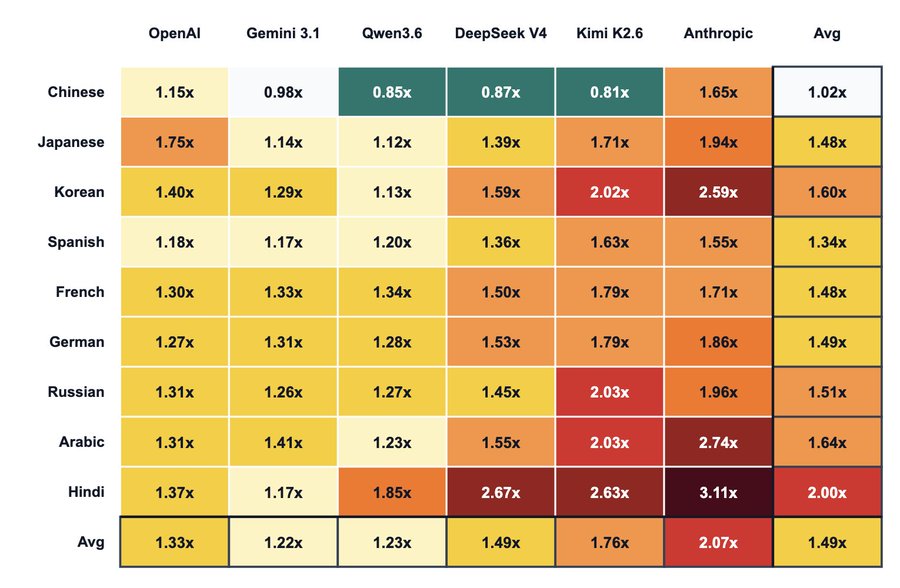
首先欣賞這張圖,圖中沒有特別標示英文(English),因為在所有模型中,英文的差異基本上都不大,Token 數大約都是1x
這裡的「1x」是指將《The Bitter Lesson》這篇論文直接丟進 OpenAI 的 Tokenizer 後得到的 Token 數作為基準,再來比較其他語言的狀況差多少。圖中的「Chinese」是指簡體中文。
關於這張圖有幾個重點:
可以看到不論使用哪種模型,英文的 Token 耗費平均而言都是最低的;而耗費最高的是印地文(Hindi)。
多語系使用者的推薦:
如果你需要處理多種語言,並想找平均 Token 數最低的模型,圖中推薦了兩個:
(a) Google 的 Gemini (1.22)
(b) 百度的 Qwen (1.23)中國廠商模型的優勢:
如果排除英文不看,有一個有趣的現象:如果你使用簡體中文,除了 Google 以外,Qwen、DeepSeek 和 Kimi 這三個由中國廠商開發的模型,處理簡體中文的效果甚至比英文還要好。對於偏好使用中文的使用者來說,狀況會好很多。繁體中文的狀況:
雖然圖表(Heat Map)上沒寫,但下方有人特別詢問繁體中文的表現。作者的回覆是:基本上跟簡體中文的效果差不多,最多只會差到 20%。避開 Anthropic Claude 的情境:
如果你是多語系使用者,或工作中會接觸到非常多種語言,建議不要使用 Anthropic Claude 家族的模型(雖然我知道很多人在使用,我也是其中之一)。
作者:CCL