給 AI 繪圖一個靈魂
講者:數據女巫 | 數據女巫 | AI Artist
活動:11/12 Generative AI 年會小聚 2025
題目:給 AI 繪圖一個靈魂

這場分享其實對我非常有啟發,因為講者不是在講「怎麼把模型調到最強」,而是回答一個現在圖生態最核心的問題:
當每天至少 3400 萬張 AI 圖誕生時,我們到底還能怎麼做出差異化?
(數字來自 2023 的 EveryPixel 估計,2025 只會更高)
講者提到,現在的 AI 內容生態已經進入 AI 垃圾時代,模型能力越來越高,產出越來越快,但「可辨識度」卻越來越低,因此創作者能做的反而不是比算力,而是「比品味」。
講者提出的框架非常務實:
如果你不建立一個自己的審美系統,你就會被淹沒在海量作品裡。
而這個審美系統,不是一句「我喜歡特效風」的 Prompt 就能交差,而是像訓練模型一樣,是一個 multi-stage pipeline,講者把整個 Pipeline 分成四層,這四層疊起來,其實就像在做一個個人化視覺生成 stack。
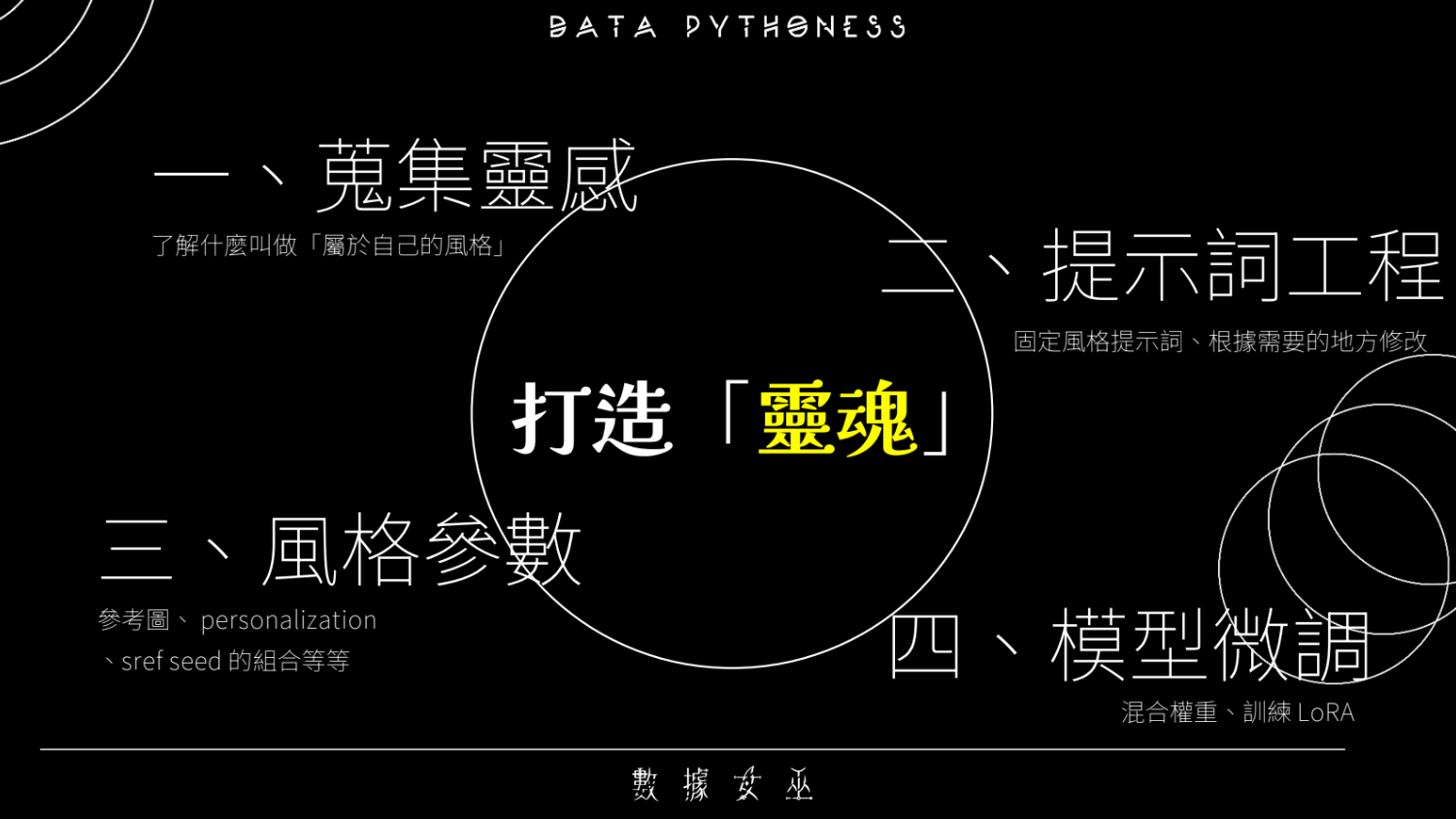
1. 蒐集靈感
講者的做法很像在建立 aesthetic embedding,她會把靈感分成兩大類:
自我偏好類:例如華麗、閃亮、水晶、奇幻
藝術史與風格系統:巴洛克、洛可可、命理視覺語彙…
這做法其實很像在為「個人風格」建立向量空間。
2. 提示詞工程
這部分講者非常系統化,會分成:
人設提示詞
固定風格提示詞
透過「人設 × 風格」組合,實際上就是在做可重複生成的視覺模板,這讓創作者能把可控性拉到比一般 AI 圖更高的層級。
3. 風格參數
這段是我覺得學習最多的的地方,講者主要使用三種方法:
Sref(Style Reference):快速固定風格向量,這個風格迥異各有千秋
seed discipline:建立可重現的風格
personalization(AI 個人化代碼):在 v7 要跑 200 張 A/B test 才能生出代碼
personalization 其實就像是「訓練一個小型 embedding」,是把個人的審美 encode 進系統的一種方式。
4. 模型微調
這是最高階的方法,你可以直接把自己的美學變成一個模型,其中包含:
LoRA 微調:如講者手動標注 Monet 作品做訓練,推薦去講者粉專看,非常有意思
模型融合:混不同 LoRA、不同 base model
SDXL 風格進化史:用百張 REVERIE 系列訓練可商用模型
這一段對 AI 技術圈的人來說非常熟悉,這就是 dataset → fine-tune → deploy 的典型 ML lifecycle,只不過 domain 換成藝術,對我來說也是非常有啟發。
聽完這場分享,我覺得講者提供的是一種由技術驅動的個人品牌形成方法論,不是在教你怎麼畫得更美,而是在教你怎麼「建立一個可持續、可辨識、可演化的個人美學」。因為在 AI 時代,藝術家之間的競爭在於跟其他使用模型的人拉出差異化。
而這份差異化不能靠運氣達成,只能靠持續蒐集靈感,並建立完整 pipeline 不停進化技術深度,培養審美決策才能從中脫穎而出。
作者:Chi