Multi-TW: Benchmarking Multimodal Models on Traditional Chinese Question Answering in Taiwan
發布囉! 作者提供:
Hugging Face 測試 : bit.ly/ntuai-Multi-TW-datasets
Podcast 研究內容 : bit.ly/ntuai-Multi-TW-podcast
LLM 的發展已逐漸從純文字走向多模態,也就是所謂的 Multimodal Large Language Models (MLLM),這種模型彌補傳統文字模型的侷限,國外也有許多針對 MLLM 的,如一直有在持續更新的 MME,然而在繁體中文領域,一直仍缺乏一個能全面評估 MLLM 的 Benchmark。過去的繁體中文評測大多只針對文字,例如 TMMLU+ ;或單一模態進行,如視覺問答資料集 VisTW;一直以來沒有跨文字、圖像、語音的綜合評測工具。
因此,最近臺灣的研究團隊推出了一個很意思的成果,Multi-TW 資料集,這是第一個專門針對繁體中文的多模態Benchmark,能同時考驗 AI 看圖辨識、聽力理解和文字問答的能力,特別的是個 Benchmark 不只看模型答對多少,還會同時評量 Latency,對現實應用很有參考價值。
1. Multi-TW 是什麼?
用白話來說,Multi-TW 是一個測試 AI 的題庫,而且內容很在地,資料集裡收集了 900 題繁體中文的選擇題,每題都不只是文字,有的附上一張圖片,有的配一段音檔,像是日常對話或廣播內容等,然後問 AI 一個理解相關的問題。
這些題目並非人工隨意編寫,而是源自台灣官方的華語文能力測驗 (即 Test of Proficiency-Huayu, 簡稱 SC-TOP) 的真實考題,這些題目本來是考人對中文聽讀能力的,現在拿來考驗 AI,非常具有真實性和挑戰性。
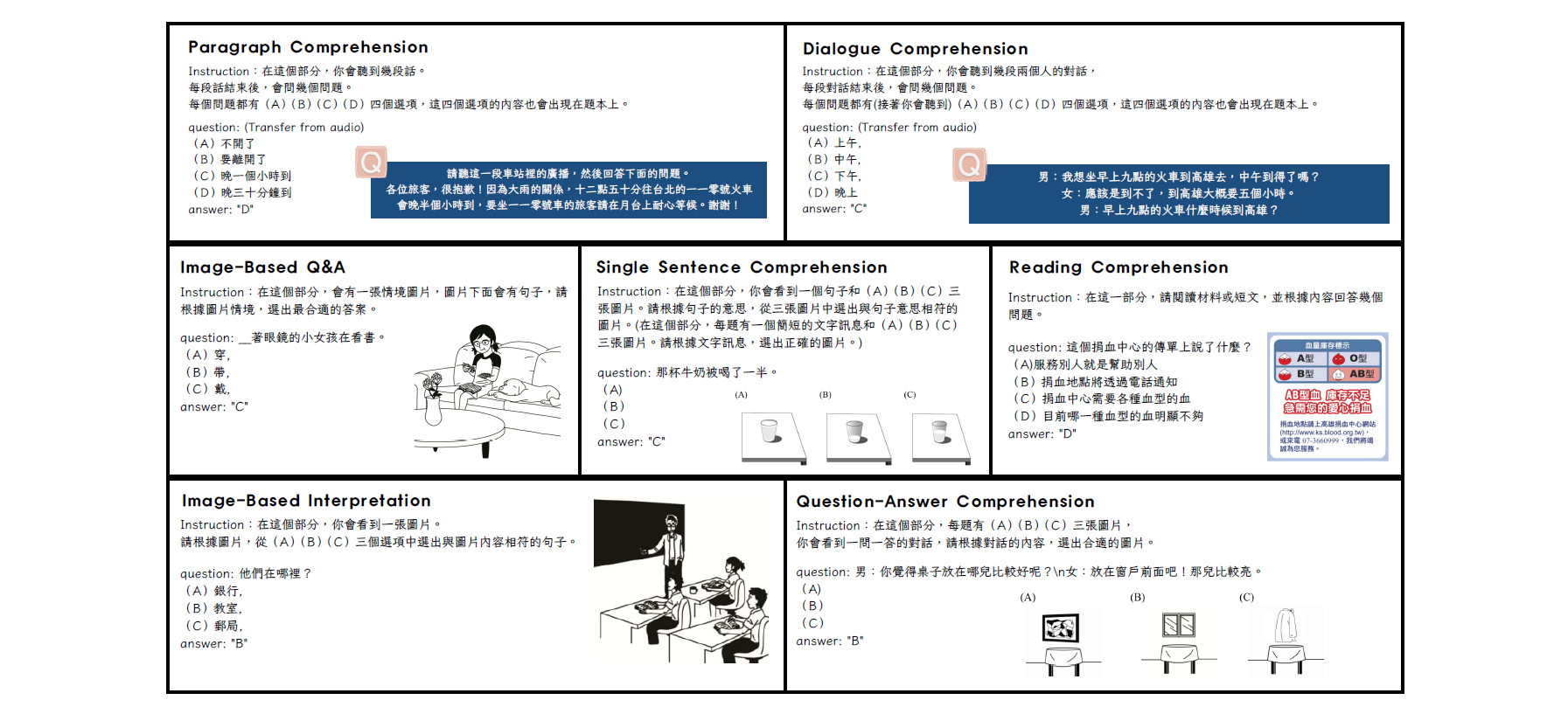
2. 測試了哪些模型?
為了瞭解現有 AI 模型在 Multi-TW 基準上的表現,研究團隊選擇了大致兩類模型:
任意模態輸入的端到端模型 (Any-to-Any MLLM):
這類模型本身就能直接吃下圖像、聲音、文字等多種輸入,然後產生答案。
模型選用 Gemini、Qwen 2.5-Omni 與 Baichuan-Omni-1.5 等
視覺語言模型+語音辨識 (VLM + ASR):
第二類是傳統做法,模型本身只擅長圖像+文字雙模態 (沒有內建聽音能力),所以遇到音檔時先用 Whisper 語音辨識把聲音轉成文字,再交給模型理解。
測試的 VLM 包括 Qwen-VL、Llama 3.2-Vision、UI-TARS、Idefics2、LLaVA、PaliGemma2 等。
整套實驗設計就是為了確保,各種主流路線的模型都能在相同的繁體中文多模態題目上進行比較,也透過這兩種路線的對比,我們可以看出模型架構差異的影響。
3. 怎麼測?
研究人員採用了零樣本設定,也就是不給模型任何額外的訓練或提示範例,直接餵每一題讓模型作答,因為是選擇題,他們在提示中告訴模型「只需輸出答案選項的字母(A/B/C/D)」,避免模型產生長篇大論,如果模型沒給出明確的A/B/C/D,就隨機猜一個答案,保證每題都有答案。
每個模型都用相同的硬體環境(NVIDIA A100 80GB) 單卡跑完全套900題,並測量處理每題的耗時;不過閉源模型是透過 API 調用,時間包含網路延遲,和地端模型不太具有可比性,所以速度分析主要還是著重在開源模型上。
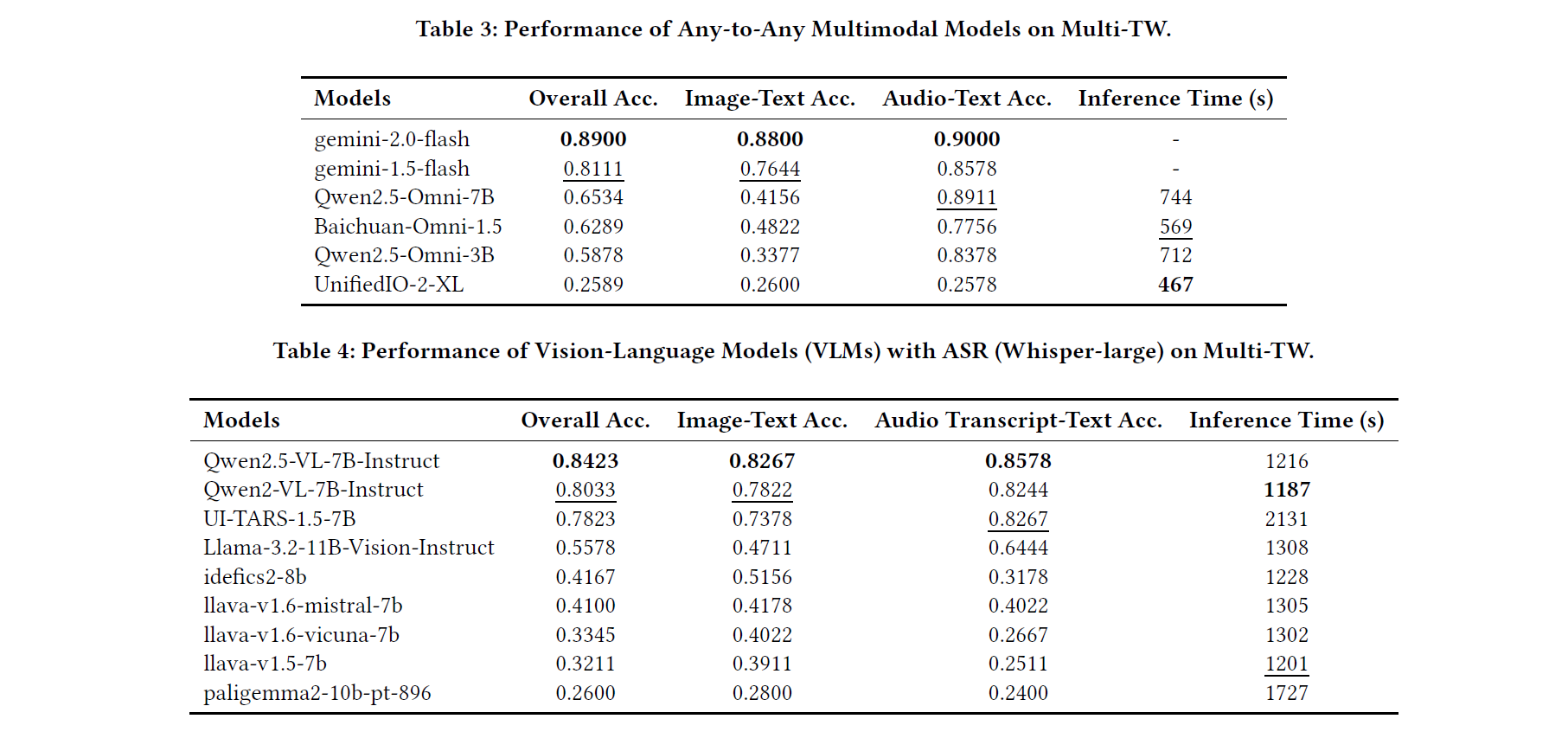
4. 關鍵發現與意涵
綜合這項研究,有幾點重要發現值得關注:
Gemini 穩居第一:
Google 的 Gemini 果然不負盛名,整體正確率約 89%,其中圖像題答對 88%、聽力題 90%,不過可惜 Gemini 是商用閉源模型,普通開發者無法直接使用 或 fine-tune。
開源 Qwen 在聽力題表現很好:
Qwen-2.5-Omni-7B 展現了意外強大的聽力理解能力,在聽力題上它答對率高達 89.11%,幾乎追上了閉園的 Gemini,這或許暗示某些開源模型其實在語音理解方面已經相當成熟。
繁體中文的圖像理解目前很難:
開源模型在繁體中文圖像訊息的理解方面明顯較弱,尤其在涉及讀取或理解繁體文字的圖片題上正確率遠低於閉源模型,這顯示目前的開源多模態模型在繁體中文環境下仍存在明顯短板,需要透過加入繁體中文資料進行微調訓練,以及強化模型的視覺模組來改善。
端到端模型推論更快:
在處理語音相關任務時,直接接受語音輸入的模型相較透過語音轉文字再進行理解的模型,有著明顯的速度優勢,在本次測試中,端到端多模態模型完成整套題目的耗時約為後者的一半,因此在講求時效性的應用中,這種架構上的優勢意味著更快的響應和更好的使用者體驗。
5. 結論
Multi-TW 為台灣帶來第一份完整的繁體中文多模態 AI 測試基準,對產學界來說,都是一套能幫助了解模型強弱、加速開發應用的好工具 。
接下來作者們還計劃:
研究簡中模型能否有效轉用在繁中上;
測更多模型延遲表現與串流推論場景;
擴充資料集任務類型,如開放問答與生成式任務 。
滿期待他們未來的發展!
附上相關卡片:
作者:Chi