論文推薦:AI Agent 評估研究
很有趣的平台,我最近在研究 AI Agent 的評估框架,看了不少文章,跟大家分享一篇適合入門的:Evaluation and Benchmarking of LLM Agents: A Survey
這篇作者把評估切成兩個面向:一是「要評什麼」,包含代理的任務表現、能力細節、可靠性,以及安全與合規;二是「怎麼評」,也就是透過靜態測試或動態互動、專門的 benchmark、量化指標、甚至 LLM-as-a-Judge 與各類評估框架來進行。
下面那張圖整理的很好。
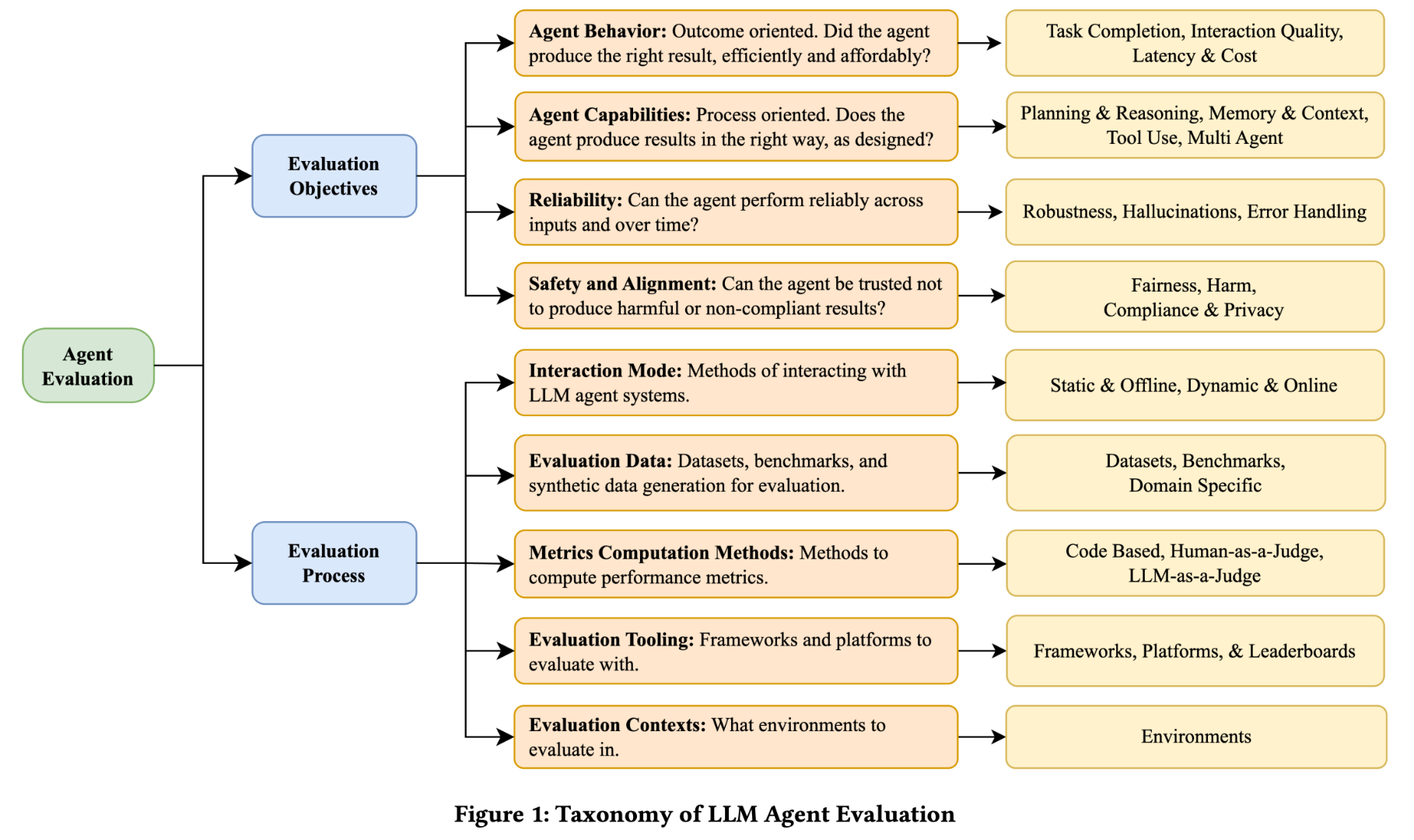
之後我覺得整體評估框架應該會往更全面且兼顧效率與成本的方向發展,不然實在太貴了。
另外安全性的議題越來越受重視,目前安全防護還跟不上 LLM 能力的提升,不久前舉辦滿大(現在好像說是最大的)的 red teaming competition 我有跟一下,主辦現在把競賽數據整理成 arxiv paper: Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition,不長,可以看看。
作者:林 Jay