淺談 Agent Team 架構實作:為什麼你的 Multi-Agent 越跑越偏?
這幾個月在 build multi-agent 系統的時候,踩了一些坑跟大家分享。
一開始我很懶,架構是一個 CEO Agent 負責管所有 agent,所有指令都透過它派發。聽起來很合理對吧,就跟真實公司一樣,有個主管統一窗口。結果發現根本管不動。
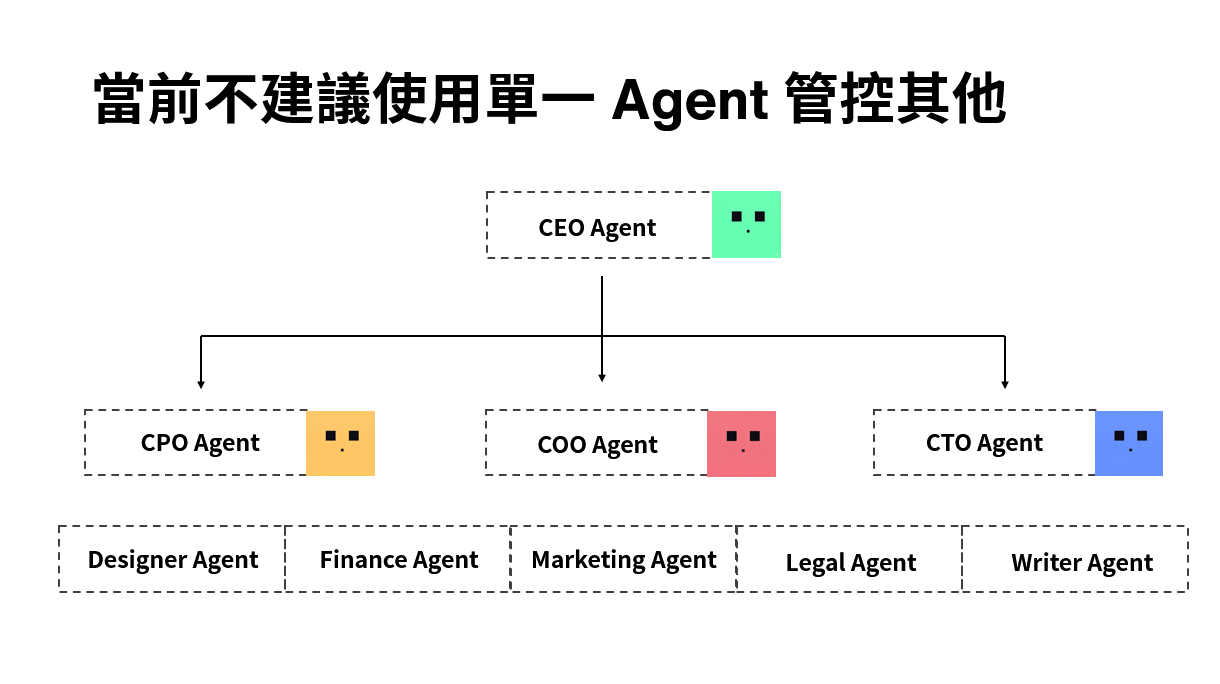
問題主要出在資訊傳遞上,你把任務傳給 CEO Agent,它理解之後再傳給下層,第一層就已經有點跑掉了。等它再往下派,二次偏誤就出現了。也就是 CEO Agent 變成了一個傳話筒,而且是一個會「自由發揮」的傳話筒。你交代它做 A,它跟下面說的可能是 A',下面再理解一次就變成 B 了。
這跟大公司的中階冗員問題幾乎一模一樣 😅
之前有一篇論文《Why Do Multi-Agent LLM Systems Fail?》也有提到這件事情,隨著對話歷史累積,資訊會在層層傳遞中衰減,每個 agent 碰到資訊缺口時會用「推測」去補,然後把推測當成事實繼續往下傳。不是 agent 不努力,是架構本身在製造誤差。
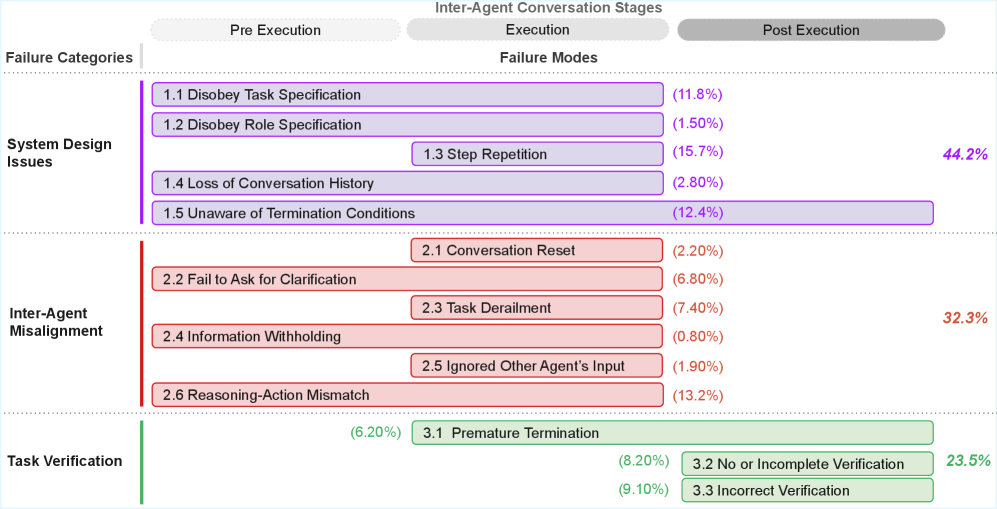
看了滿多人在討論 Supervisor 模式的單點瓶頸問題,甚至有 Claude 跟 Devin 團隊直接公開對嗆「到底該不該做 multi-agent」,核心爭議也是 context 無法有效共享這件事,目前社群裡也還沒有共識。
後來我換了架構,改成 C-level 平行模式。現在我直接管 CPO、COO、CTO 三個 Agent (還有數個其他功能的 Agent),每個 Agent 有自己明確的職責範圍,不需要透過任何中間層轉述。C-level 底下最多再 spawn 一個 sub-agent 處理具體執行,但指揮鏈就到這裡為止,不再往下疊。
另外我讓各 Agent 之間可以在 Discord 互相 mention、直接溝通協調,不用每件事都回報給我再轉出去,但我也看的到他們溝通協作的過程,不是 A2A 直接溝通,這樣整個系統的 context 乾淨也透明很多,目前測試兩周,他們彼此協作起來真的滿有趣也確實有成效。
這個架構改完之後,偏誤明顯少了。
我個人覺得,現在很多人在設計 multi-agent 時,直覺上會想複製人類組織的金字塔結構,因為這樣「感覺有秩序」。但 LLM 每次推論都有一定的不確定性,層數越多,誤差累積越快,而且人類的溝通方式本來就不完全適合 agent。
以目前的框架來說,我覺得扁平化可以少資訊衰減的路徑。
不過這條路要繼續走,完全扁平其實也不是終點,更成熟的做法是「對外保留一個統一入口,對內才做平行分工」。也就是說,使用者跟系統溝通時還是透過一個窗口,但這個窗口的工作只有一件事,判斷任務該交給誰,然後放手讓各 C-level 去執行,不插手細節、不轉述內容,我現在 DC 上的結構更類似這樣,大家有興趣再分享。
另外時做到現在有一點我覺得很重要,就是 trace 跟每個 agent 的決策紀錄,應該從第一天就設計進系統裡,不是出事了才回頭補 log。這個我之前吃過虧,debug 的時候根本不知道某個 agent 是基於什麼資訊做的判斷,只能通靈,現在我們所有紀錄都會上 Linear 與 Github issue。
等哪天你發現某個 C-level Agent 開始變成新的瓶頸,再針對那個局部做調整就好,不需要一開始就把整個架構搞得很複雜。
簡而言之「單一 CEO 全管」跟「完全扁平無中心」都是極端,真正穩的系統通常長在中間某個位置,視任務複雜度慢慢往外長。這是我目前的想法,還在持續迭代中,說不定下個月又換一輪 🫠
有在玩 multi-agent 的朋友歡迎分享你的架構,踩過類似坑的也歡迎在下面取暖 🙏
作者:Chi