Cofacts 跟「字幕由 Amara.org 社群提供」說再見
講者:Johnson | Cofacts 真的假的 | 發起人與工程師
活動:9/17 Generative AI 年會小聚 2025
題目:Cofacts 跟「字幕由 Amara.org 社群提供」說再見

演講介紹
講者分享了他們在做 Line訊息回報機器人與查證協作社群時,逐字稿功能背後的技術需求,說實在這個議題很有趣,因為現在假訊息越來越多,受騙的人群也越來越多,因此能在 Line 上直接辨識是否為假訊息,是一個對大眾很有益的題目。
他們處理的對象高達 23 萬則圖文影音,量體非常大,他們會用先用逐字稿功能取得影音的文字,再用 electic search 去查是否與資料庫內容有相同,因此在這個基礎上,逐字稿功能就變得非常重要,講者分享了許多具體實作會遇到的議題,非常有趣,我也是第一次意識到這類議題的難度所在:
即時性:使用者是在線等待的,不能讓使用者等太久
完整性:為了後續要做 Elastic Search 去查相似內容,逐字稿功能要完整而且可檢索,有檢索與查證需求。
複雜性:影片的守備範圍很超廣,各種排列組合,如下:
無人聲無文字
無人聲有文字
有人聲無文字
有人聲有文字
有人聲有翻譯 (但翻譯可能跟影片的語言不一樣)
有人聲亂翻譯 (直接亂翻譯)
講者講到他們採用的技術演進過程,滿符合 AI 整體發展的趨勢XD:
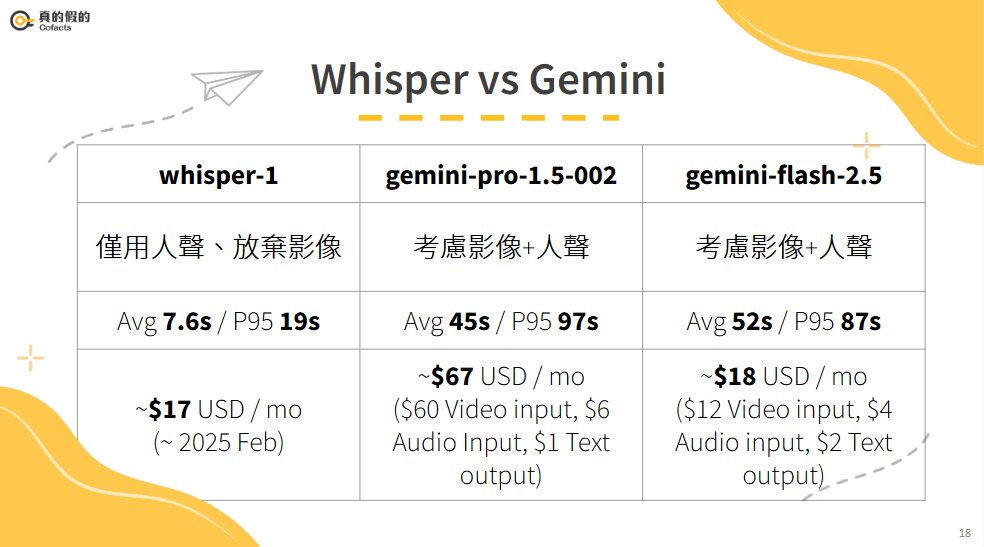
早期 (OpenAI Whisper API)
速度不錯,19 秒內就能拿到逐字稿。
成本大概 17 美金/月。
但問題是:沒有聲音或純音樂就壞掉。
嘗試過音量偵測,但音樂會干擾。
需要 Voice Activity Detection (VAD) model 來輔助。
後來 (Gemini Flash)
Gemini 能同時處理「視覺 + 聲音」,只要有人聲或文字就能輸出。
價格便宜,能補起影像資訊。
缺點:
沒人聲、沒文字就完全沒用。
30 分鐘會議 OK,但 1 小時長片就會失效。
最終,該選哪個 model,完全取決於你的個案:
如果是短影音、多人上傳,即時性 > 成本。
如果是會議逐字稿,長度限制 > 視覺輔助能力。
我的體會
假訊息辨識不是單純的 NLP 問題,而是「語音 + 視覺 + 即時」的組合拳,逐字稿看似小工具,其實是能不能讓 23 萬則資料被檢索、被比對的核心關鍵,我個人很希望這個項目能做起來,讓大家不再受騙。
作者:Chi