數發部:臺灣主權AI訓練語料庫
這幾天在整理資料時,終於花時間把 數位發展部 推出的「臺灣主權 AI 訓練語料庫(TAIC)」看過一輪,這是一個從政府端建立起一個具台灣特色、正體中文為主的 AI 語料資源平台。
為什麼要建立「主權 AI 語料庫」?
這幾年如果你有碰過繁體中文 LLM,不管是自己訓模型、微調或是做地端應用,應該都會遇到資料不足或不夠精確的問題,以往中文語料無論開源或商用,往往以簡體為主,但若拿此資料來訓練 AI,那麼 AI 在台灣語言使用與文化表現上非常容易出現偏差,這在台灣特殊的地緣政治下,顯得格外敏感。
在跟某些產商或業主接觸時,常感受到大家會以為只要把模型換成支援繁體中文,或把回答轉成繁體中文,就算是「台灣版 AI」,但實作者都知道,真正的問題從來不是字形,而是語境與世界觀,舉個例子你問 AI 政策,它會給你不屬於台灣的制度;或你問生活用語,它會出現「看得懂,但不會這樣講」的回答。
過往有許多前輩推出各式台灣的語料集,如以下示意(有缺請給我說)
TAIC 簡單來說就是幫你把能安心用來訓模型的材料先準備好,目前釋出的語料以政府與公共資料為主,涵蓋政策、教育、文化、環境等領域,並以繁體中文與台灣語境為核心。這些內容本身不一定最好用,但它們的來源清楚且授權明確,讓模型訓練者不再需要在每一筆資料前面問這是否合法。
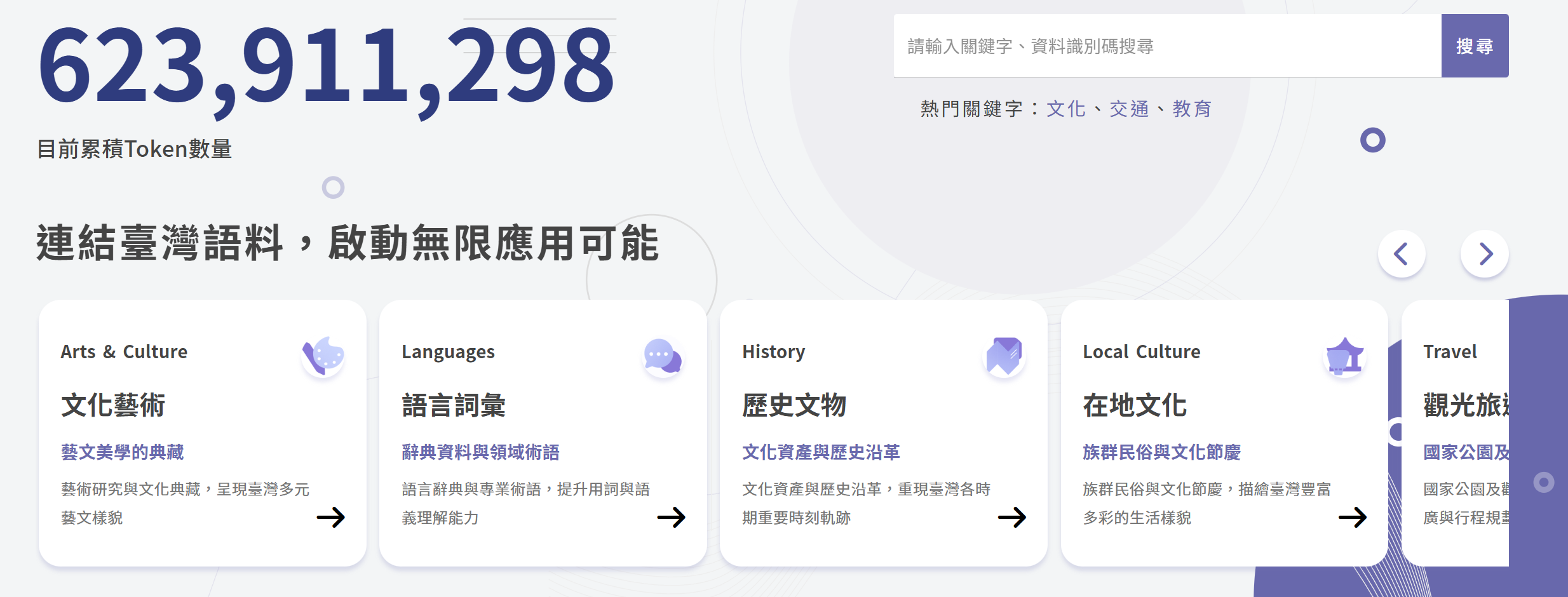
TAIC 目前的規模與內容
目前啟動後的語料庫已累積:
超過 200 個政府機關資料來源參與上架,涵蓋中央各部會。
超過 2,000 筆資料集,累計 超過 6 億個 tokens
資料領域多元,包括 語言、文化、教育、生物、地理環境 等內容,並包含正體中文語言學資料、歷史文化資產、族群與節慶、專業術語與百科知識等。

語料授權與使用方式
過去很多做技術團隊,其實不是技術做不到,而是卡在法務與風險上,如資料抓到但不敢用;或模型訓練出來後,但不敢公開,最後只能一直停在實驗階段。在 TAIC 的設計中,數位發展部也意識到這個痛點,並與經濟部智慧財產局合作推出《台灣主權 AI 訓練語料授權條款(第 1 版)》,透過一次性、明確界定用途的授權方式,明確界定資料開放與使用條件,避免訓練資料著作權爭議,這件事對研究單位、學術界、甚至新創來說都是一個很大的門檻解除
使用者申請方式:
TAIC 明確把語料分成兩大類,對長期在做模型訓練的人來說,這樣的區分其實非常清楚哪些資料只能訓模型;哪些資料可以拿來做產品,而不再有模糊的灰色地帶。
第一類是僅授權用於 AI 訓練的語料,這類資料是由資料提供單位依《台灣主權 AI 訓練語料授權條款(第 1 版)》釋出,只能用於模型訓練與學習,不得另作他用,這也是 TAIC 比較關鍵也比較特別的地方。使用這類語料前,必須先申請帳號並通過審核,整個流程與使用邊界其實訂得相當清楚,數位發展部通常會在約 7 個工作天內完成審核,通過後才會開通對應的下載權限。
第二類則是政府開放資料,同步自政府資料開放平台,採《政府資料開放授權條款-第 1 版》,允許不限目的的自由使用,包含重製、改作與開發衍生產品,當然也包含 AI 訓練在內,且無須申請帳號即可下載,適合快速測試或一般研究用途。
在檔案格式上,目前提供的多為 PDF 與 JSON 等通用格式,也符合 FAIR 原則,也就是資料具備可查找、可取得、可互通與可再利用的特性,對實際進入模型訓練流程來說是相對友善的設計。
但這還不是終點
站在實作者角度,這個語料庫現在還不到拿來就能訓出好模型的階段,距離真正好用,還需要更多自然語言資料、更細緻的標註、更貼近實際模型流程的整理方式,但資料基礎建設本來就是慢而且不討喜的工程,不是一蹴可幾的事情,還是很開心政府帶頭開始做這件事,這對原本長期在做繁體中文 LLM 的人來說,也許不是一個讓人熱血沸騰的消息,但我認為是一個讓人願意繼續走下去的支撐。
作者:Chi