MLLM Tutorial, CVPR 2025
近年多模態大型語言模型 (Multimodal Large Language Models, MLLMs) 快速崛起的同時,相關的評估Benchmark 也如雨後春筍般出現,然而這些基準在有效性與科學嚴謹性方面仍存在爭議與挑戰,這個 CVPR 2025 舉辦的 MLLM Tutorial 系列,非常好的針對這些問題進行系統性梳理與討論,協助研究者與實務開發者建立更全面且可重現的評估框架。
可惜沒有影片重播了,以下附上這個 Tutorial 的各個 slides,覺得滿不錯推薦給大家
內容概述:
Part 1: Background and Introduction [Slides]
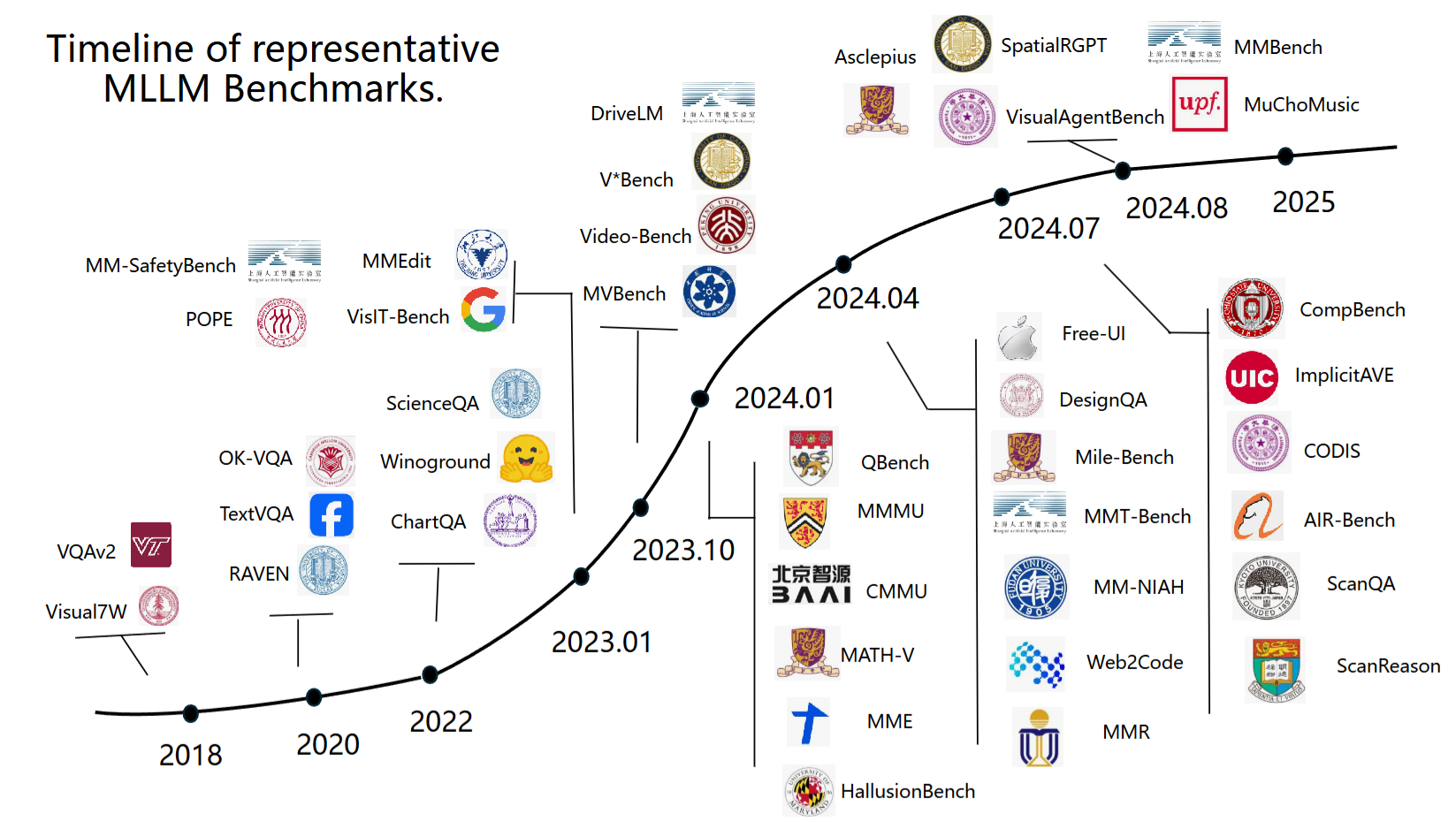
Part 2: Existing MLLM Benchmark Overall Survey [Slides]
Part 3: Vision-Language Capability Evaluation [Slides]
Part 4: Video Capability Evaluation [Slides]
Part 5: Expert-level Discipline Capability Evaluation [Slides]
Part 6: Beyond Evaluation: Path to Multimodal Generalist [Slides]
Part 7: MLLM Hallucination Evaluation [Slides]
作者:Chi