LFM2-Audio: An End-to-End Audio Foundation Model
過去我們談語音 AI,幾乎都要經歷三段式流程:
ASR:把語音轉成文字
LLM:理解並生成回覆
TTS:再合成語音。
這樣的架構雖然可行,但在真實互動中往往顯得笨重,延遲高、資訊流失,而且每一段模型都各自訓練、難以優化。
STS 的模型其實就是在解決這個痛點,有興趣可以參考以下觀點卡:
Liquid Audio 這次釋出 LFM2-Audio-1.5B 就是一種 STS 模型,它是 LFM2 系列的延伸,但首次讓語音與文字成為「同等一級的模態」。換句話說,這個模型可以同時聽懂語音、回語音,也能在需要時輸出文字或理解文字輸入,完全不需要再切換模型或模組。
最有意思的是它在音訊表示上的取捨,一般語音模型會先把聲音壓成離散 token,再丟進語言模型中處理;但 LFM2-Audio 選擇讓「輸入」維持連續訊號,僅在「輸出」階段才離散化。
這讓模型能保留更多聲音細節,像音色與語氣,但同時又能用傳統 next-token 的方式訓練生成,輸出階段一次可預測八個音訊 token,也就是說它能更快地「講話」,而且聲音更自然流暢,不像以前有卡頓感。
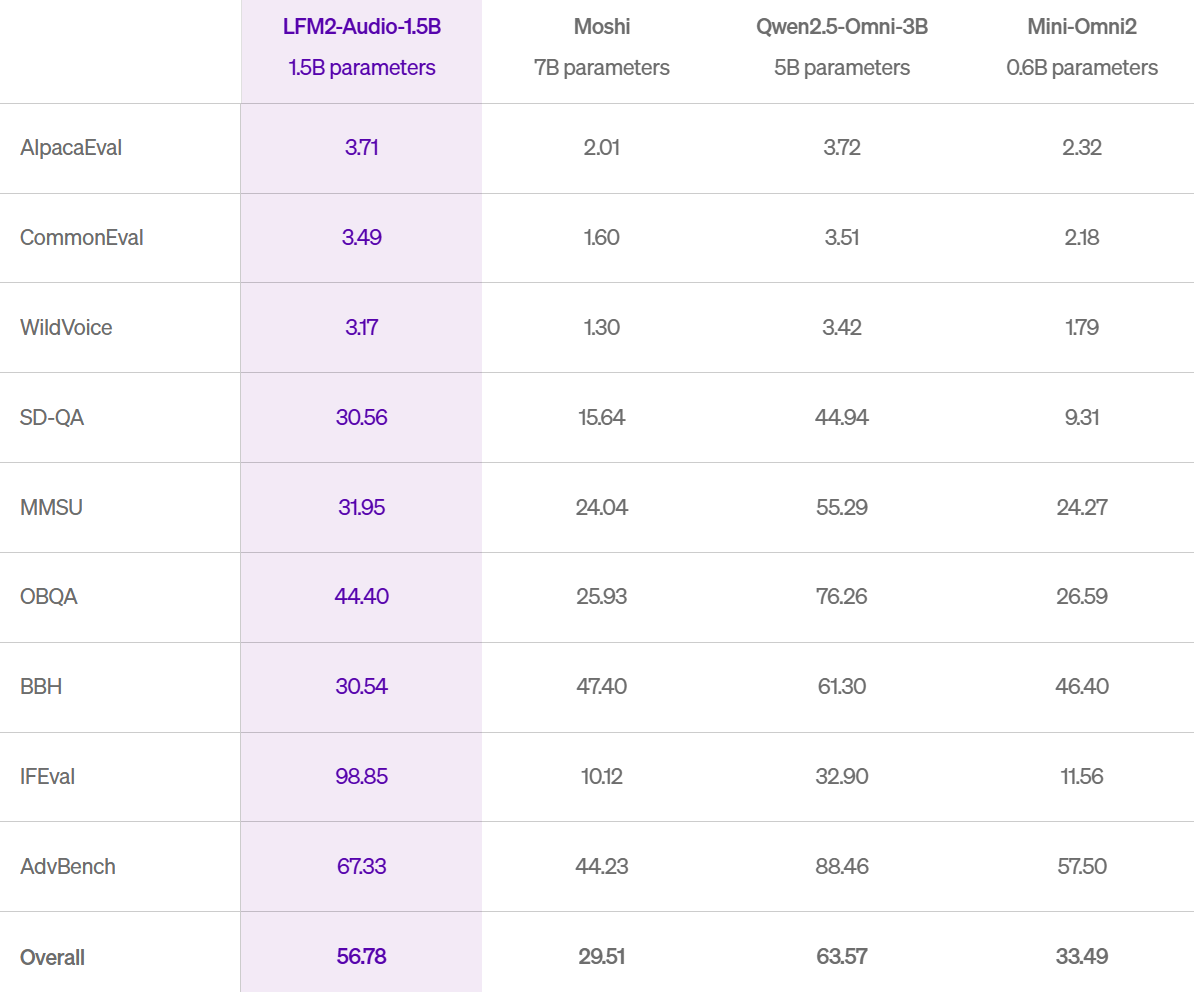
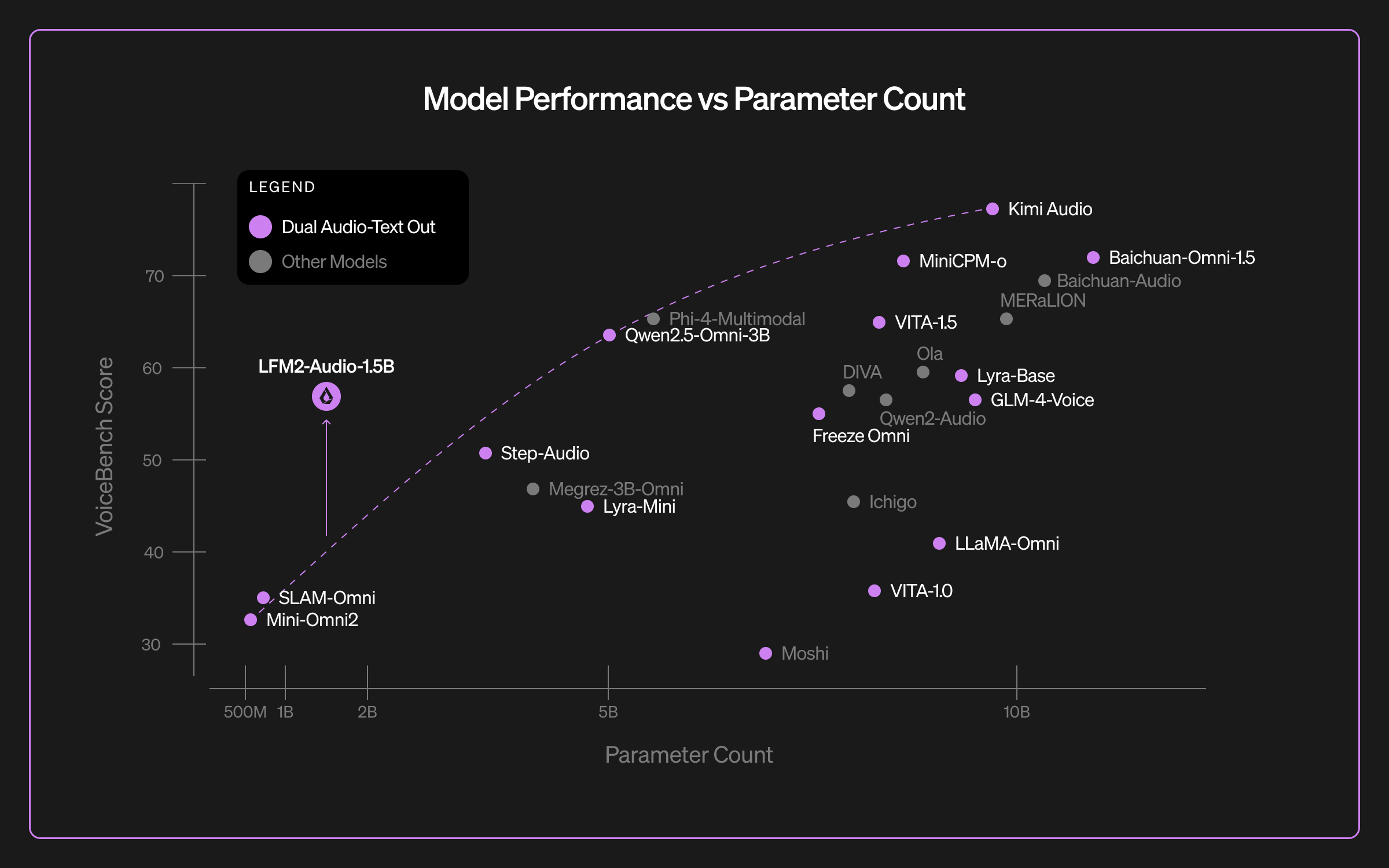
效能上這模型的表現還不錯,只有 1.5B 大小,卻在 VoiceBench 九項音訊互動測試中拿到 56.8 分數,接近 5B 參數的 Qwen2.5-Omni-3B;ASR 準確度甚至可與 Whisper-large-v3 相比。
延遲則是最讓我驚豔的,end to end 不到 100 毫秒,對即時語音對話來說幾乎是即開即說的體驗。
過去需要三個模型串起來的語音系統,而如今可以用一個 backbone 完成,STS 不只是會講話的 LLM,而是具備聽、想、說一體化能力的多模態基礎模型,且模型又小。
預估未來車載語音助理、即時翻譯、到語音版 RAG 聊天機器人等都會廣泛啟用這個架構。
作者:Chi