Kimi K2 Thinking
在 Linkedin 看到有人針對 Kimi K2 Thinking 做了整理,幫大家快速翻譯:
我剛看到 Kimi K2 Thinking 的釋出。
從這次的版本來看,根據他們公開的 benchmark,開源權重(open-weight)的大模型似乎暫時領先於封閉模型(proprietary)。
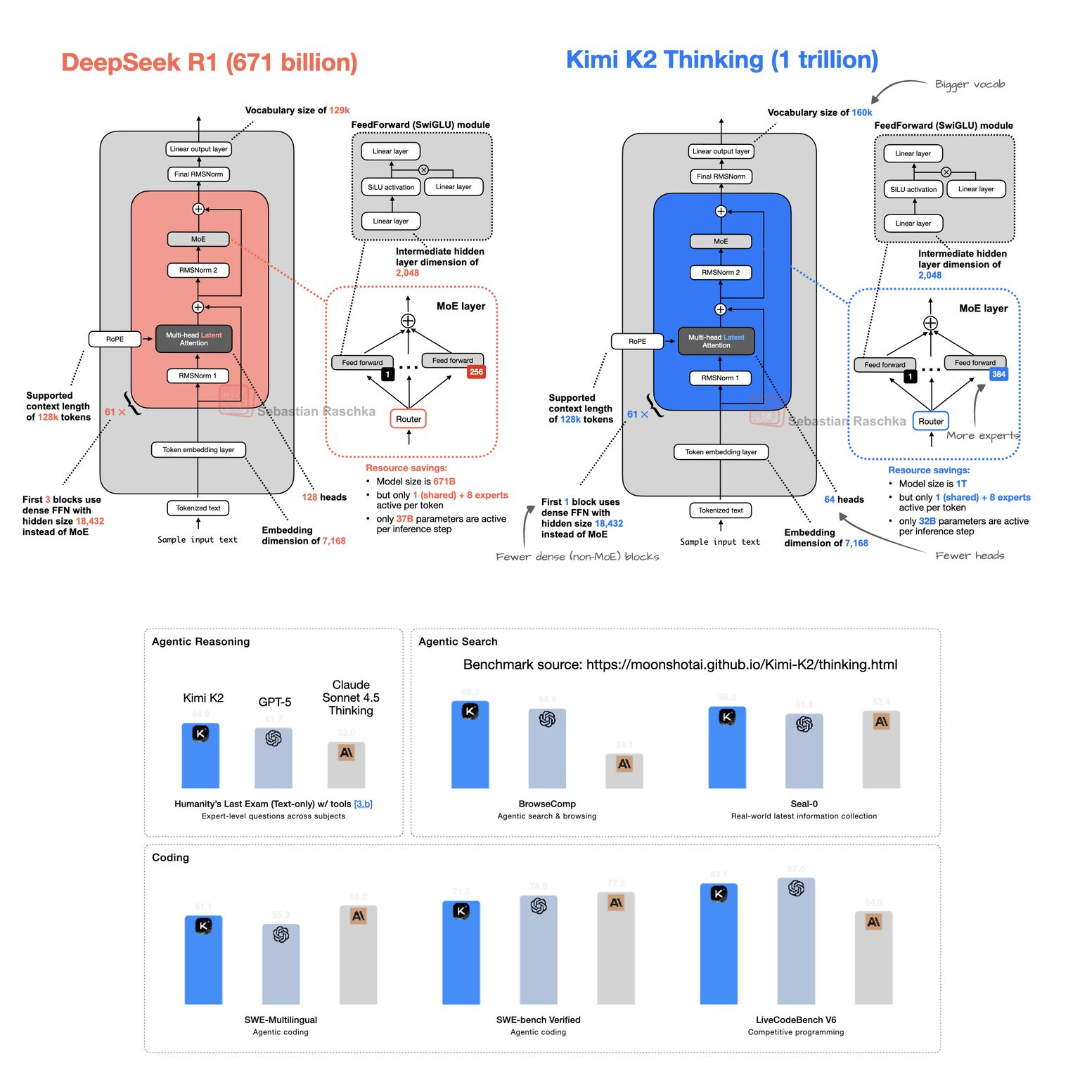
Kimi K2 的底層架構是基於 DeepSeek V3/R1,以下是兩者的並排比較:
注意力頭數減半(64 vs. 128)
每層 MoE 的專家數增加約 1.5 倍(384 vs. 256)
詞彙表更大(160k vs. 129k)
每個 token 啟用的參數約 320 億(vs. DeepSeek R1 的 370 億)
密集 FFN block 數量更少(MoE 前的 dense 層)
整體來說,Kimi K2 可以視為 DeepSeek V3/R1 的「輕度縮放版」,而性能的提升主要來自於 資料與訓練配方(data & training recipes) 的優化,希望之後能看到更多細節。
另外我覺得若能在這次的 benchmark 中加入 DeepSeek R1 的數據,讓我們看到從 2025 年 1 月到現在的具體進步,會更有意思,說真的,現在已經進入「每週都有新大事」的 LLM 時代了。
也有人提到,99% 的功勞其實來自於 data 的改進,而不是 architecture的調整,
我滿認同,至少在這例子上。
作者:林 Jay