LLM 其實很挑表格格式
這篇實驗做了一件很多人忽略、但每天都在踩的坑,同一批資料,用不同表格格式餵給 LLM,準確率會差多少?
研究者用 1,000 筆合成員工資料 (8 欄位),對 GPT-4.1-nano 連續發 1,000 題查詢,如「Grace X413 有幾年資歷?只回數字」,重複測 11 種資料格式,量化準度與 Token 花費。
結果:
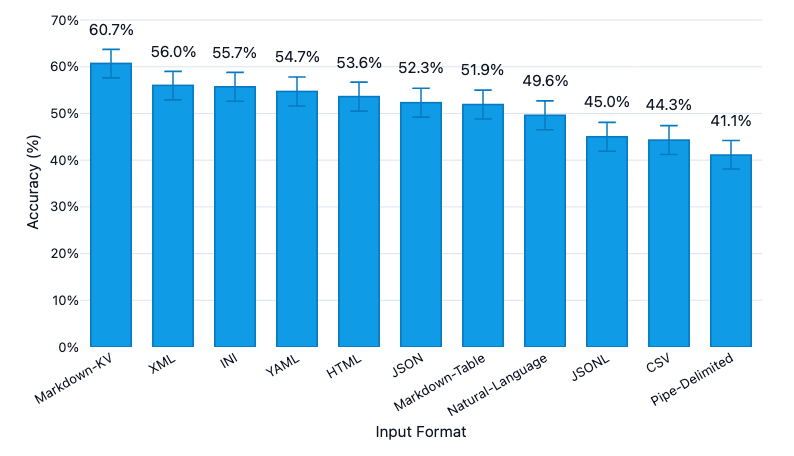
Markdown-KV (key: value) 最高分 60.7%;
CSV / JSONL 竟然出乎意料墊底(44.3% / 45.0%);
格式真的很重要,而且準度常常要用 Token 換(Markdown-KV 比 CSV 多 2.7 倍 Token)。
作者:jiaweiOrz