AI 不缺大腦,缺的是能長期累積與管理的記憶系統
最近在研究 AI Agent 的記憶機制,讀到一篇 survey 蠻有啟發的:
Memory in the Age of AI Agents: A Survey — Forms, Functions and Dynamics(Hu, Yuyang et al., 2025)
我個人覺得這篇最有價值的地方,是它點出了一個大家都在迴避的問題:
我們現在講「記憶」,到底在講同一件事嗎?
有人把文件檢索進來叫記憶(RAG),有人把上下文壓縮排程叫記憶(context engineering),也有人在搞模型內部的長上下文機制。這些東西都很重要,但目的完全不一樣。
真正的「代理記憶」更像一個會成長的系統,它要決定什麼值得記、怎麼更新、什麼該忘、什麼時候拿出來用。這跟單純把資料塞進 context window 是兩回事。
這篇論文我覺得有三個關鍵貢獻:
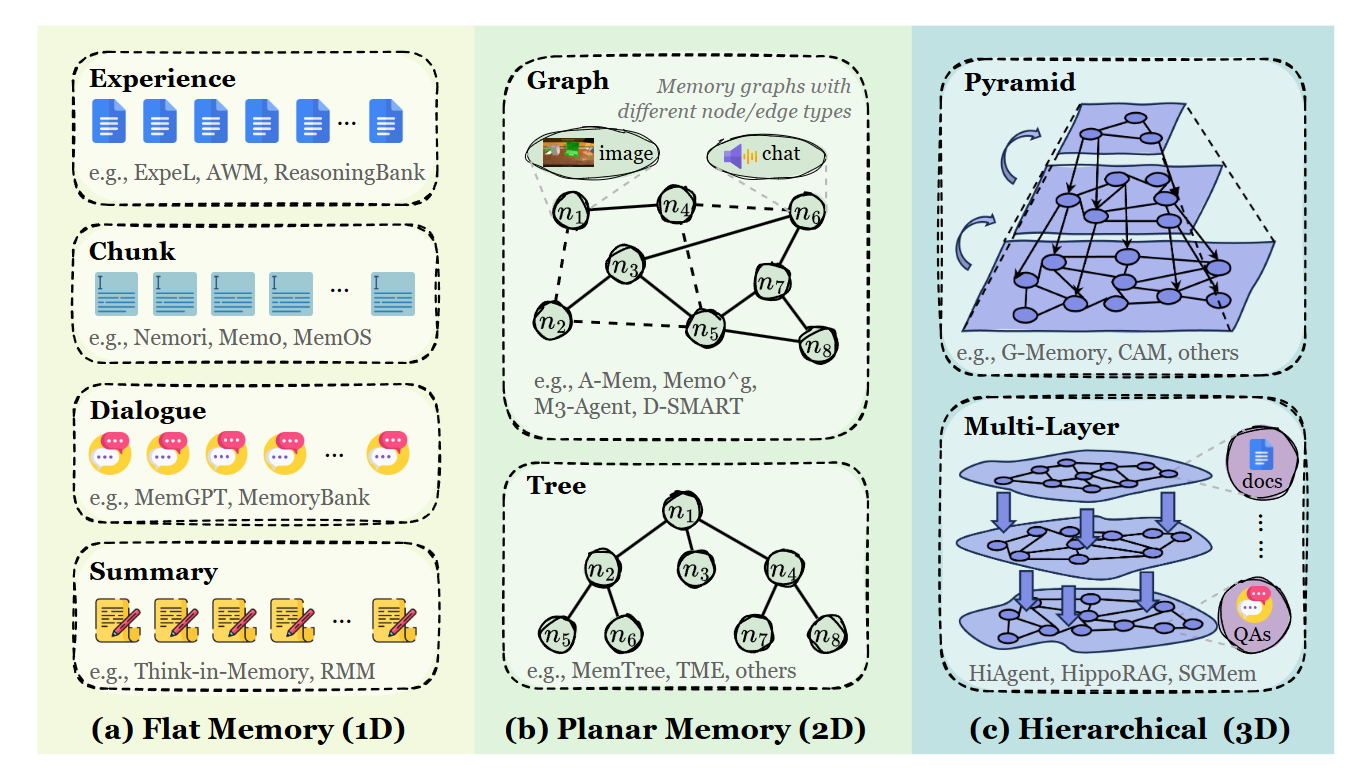
一、提出 Forms–Functions–Dynamics 三維分類框架
把「記憶」從一個模糊的概念,拆成三個可以工程化討論的維度:
形式(Forms):記憶的「載體」是 token-level、parametric、還是 latent
功能(Functions):記憶的「用途」是 factual、experiential、還是 working
動力學(Dynamics):記憶「怎麼運作」,包含 formation、evolution、retrieval
老實說這個框架蠻清楚的,之後跟團隊討論記憶相關架構時,可以用這組語言對齊,不用每次都先花半小時釐清彼此在講什麼。
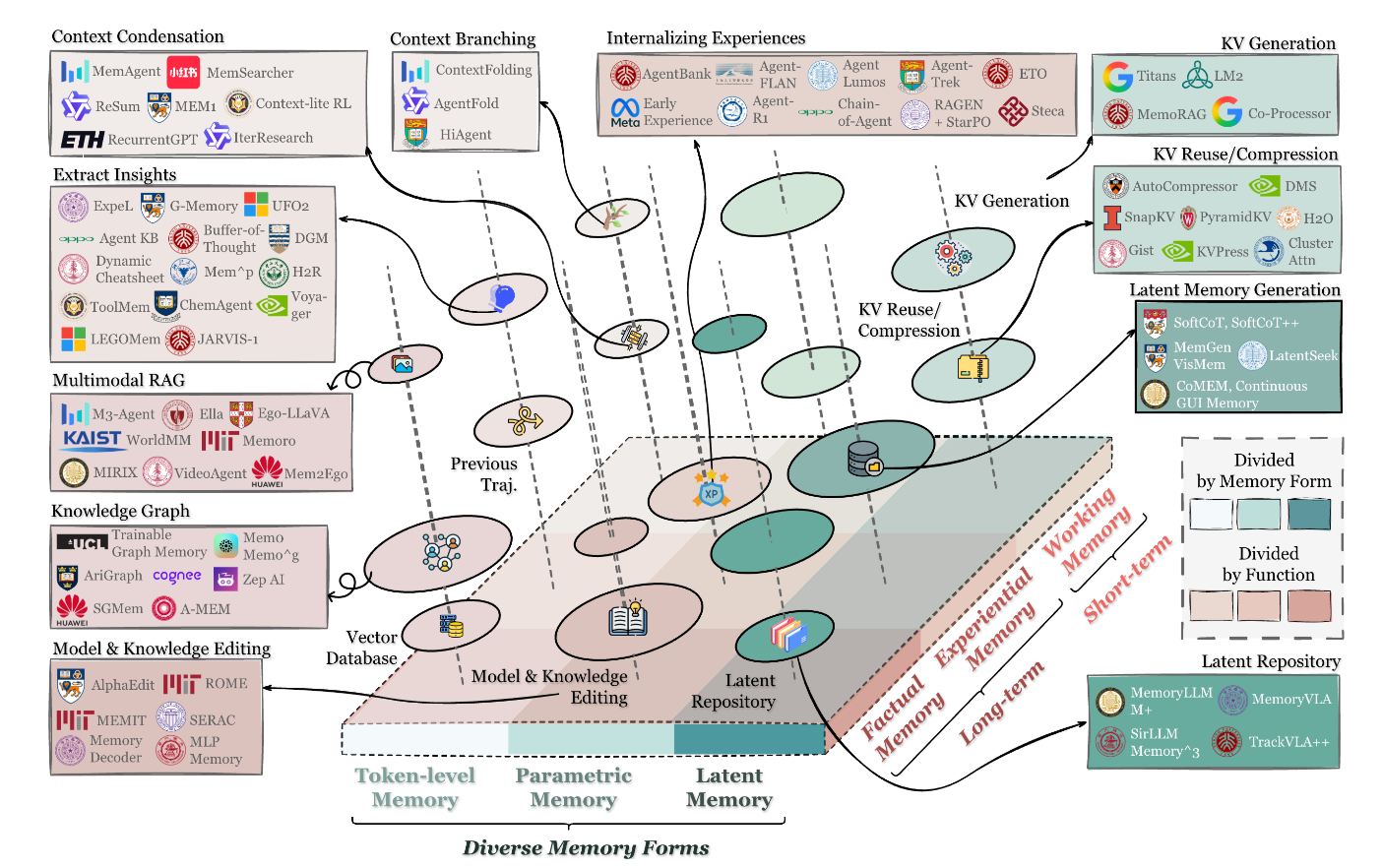
二、把常被混為一談的東西拆乾淨
論文特別區分了這四種常被統稱為 memory 的東西:
LLM 內部記憶(長上下文、KV cache、模型架構改動)
RAG
Context engineering
Agent memory
這點對工程實作特別有用,因為你選什麼方案,取決於你要解決的是哪一種「記憶」問題。搞混了就會拿錘子釘螺絲。
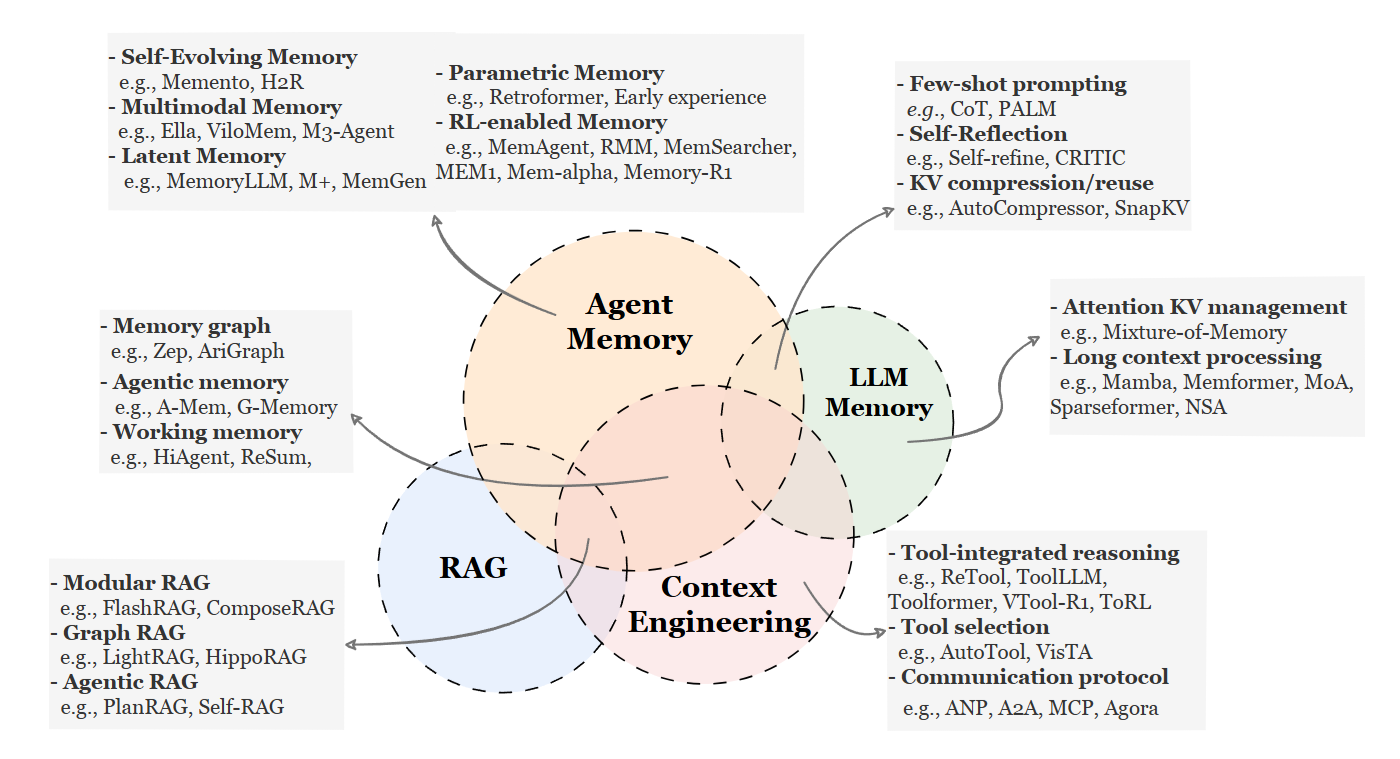
三、整理了大量 benchmarks 與開源 frameworks
它用表格彙整了可以拿來做研究或做產品的資源,讓你選型跟比較不用從零開始。這對想快速切入這個領域的人來說蠻實用的。
我自己讀完最大的感覺是,記憶這塊現在還很早期,大家都還在摸索。模型能處理 100K+ tokens 聽起來很猛,但實際上「lost-in-the-middle」的問題還是在,有效上下文遠小於帳面數字。
不過外部長期記憶在特定場景已經能看到效果了,像 MemGPT 在跨 session 記憶檢索的任務上,把正確率從 32–39% 拉到 67–93%,這落差蠻驚人的。
真正難的地方在「一致性、時間推理、更新跟遺忘」。MemoryAgentBench 的測試顯示,context 從 6K 拉到 32K 時效能會大幅崩落,現階段瓶頸很明顯。
然後結構化記憶(知識圖譜、GraphRAG 這類)看起來是下一個主戰場。單純向量 RAG 已經撐不住多跳關聯跟全域理解的需求了,GraphRAG、HippoRAG 2、AriGraph 這些工作都在往結構化索引的方向走。
如果你也在做 AI Agent 相關的東西,這篇 survey 蠻值得花時間讀一下的,至少可以幫你把「記憶」這個字的含義對齊,不曉得大家在實作上有沒有碰過記憶相關的坑?
作者:Chi