LLGuidance:把結構化輸出做的又對又快
這篇是我看 Michał Moskal、Harsha Nori 等人在 Microsoft 發表的 LLGuidance 技術筆記後,整理的重點與實務建議,這篇主要在講,如何在不拖慢推論的前提下,讓 LLM 乖乖吐出結構正確的 JSON或程式碼。
這件事為什麼重要?
靠運氣產生格式正確的 JSON,遲早會在「tool calling/codegen/抽取欄位」這類環節出錯,以前傳統解法是抽到不合法就丟掉重抽,也就是 rejection sampling,但這會卡住下一個 forward pass,延遲會很高。
LLGuidance走的路徑是,在每一步生成前,先在 CPU 端算出「哪些 token 可用」的 token mask,把不合法的 token 機率設成 0,再交給 GPU 做 softmax。只要算遮罩的時間 < 一次 forward pass,也就幾乎沒有額外延遲,而這也是這篇的核心,把語法檢查移到 GPU 等待的那段時間。
速度從哪裡來?
論文把加速來源分成四個元素,每一個都能帶來一個數量級的收益:
Lexer / Parser 拆分
用符號正則先切詞(lexing),只有在必要時才進 Earley parser。實務觀察:99% 的 token 檢查停留在 lexer,就過關了。Token Trie
把 tokenizer 的 byte 串建成 prefix tree。當某個 byte 在當前狀態「不可能」,整棵子樹一次剪掉。Sparse mask 的情境(例如整數正則) 特別有效。低階最佳化 (Rust)
對 trie、regex 自動機、parser 狀態做記憶體布局與分支預測優化,作者實測到 ~13 cycles / node 的掃描效率。Slicer (新招,值得看)
把 tokenizer 依某些寬鬆的正則片段分成幾個 slice,例如 JSON string 中允許的字元範圍與長度上限。若某 slice 整段都被 lexer 接受,就直接套用預先算好的 mask,略過整個 trie 走訪。這招專打 dense mask(例如長字串)這類通常最慢的角落。
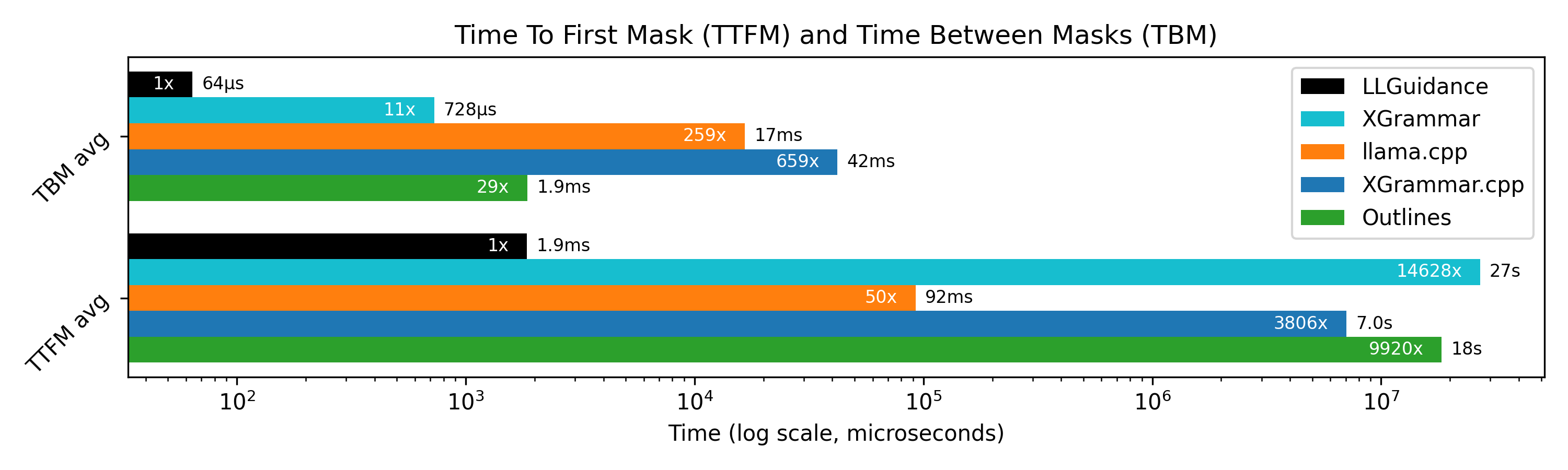
在名為 MaskBench 的挑戰性場景裡,LLGuidance 平均 ~50μs 就能算完一次 mask,啟動時間 ~2ms。這數字對線上系統很關鍵,因為你多半會 batch 多路請求,CPU 的遮罩計算能與 GPU 前向重疊,尾延遲不會被放大。
跟其他框架的差別
LM-format-enforcer / llama.cpp grammar:也是動態算 mask,但一個用 Python、另一個用回溯 parser,速度上吃虧 (少了 lexer,或在 dense 區域不夠省)
Outlines:預先把整個自動機所有狀態的 mask 都算好,啟動成本與記憶體開銷大、限制語法彈性;反之LLGuidance 改走隨用隨算,幾乎零啟動負擔。
XGrammar:做部分預算,極端情況會花到秒級或更長;fit 到特定輸入時很快,但穩定性不如 LLGuidance。
LLGuidance 的定位很清楚:通用 CFG + regex lexer、零 (或說極低) 的預算、最壞情況也在可控範圍,用這種工程曲線,才能扛得住生產流量。
給實作者的落地備忘
以下是我覺得對線上服務最有用的操作面建議:
把「結構」寫進 grammar,不要寫在 prompt
JSON Schema、語言文法該長什麼樣,先用 LLGuidance/Lark 擴充語法描述,讓模型只在合法區間取樣。主動「限制長度」與「約束字元集」
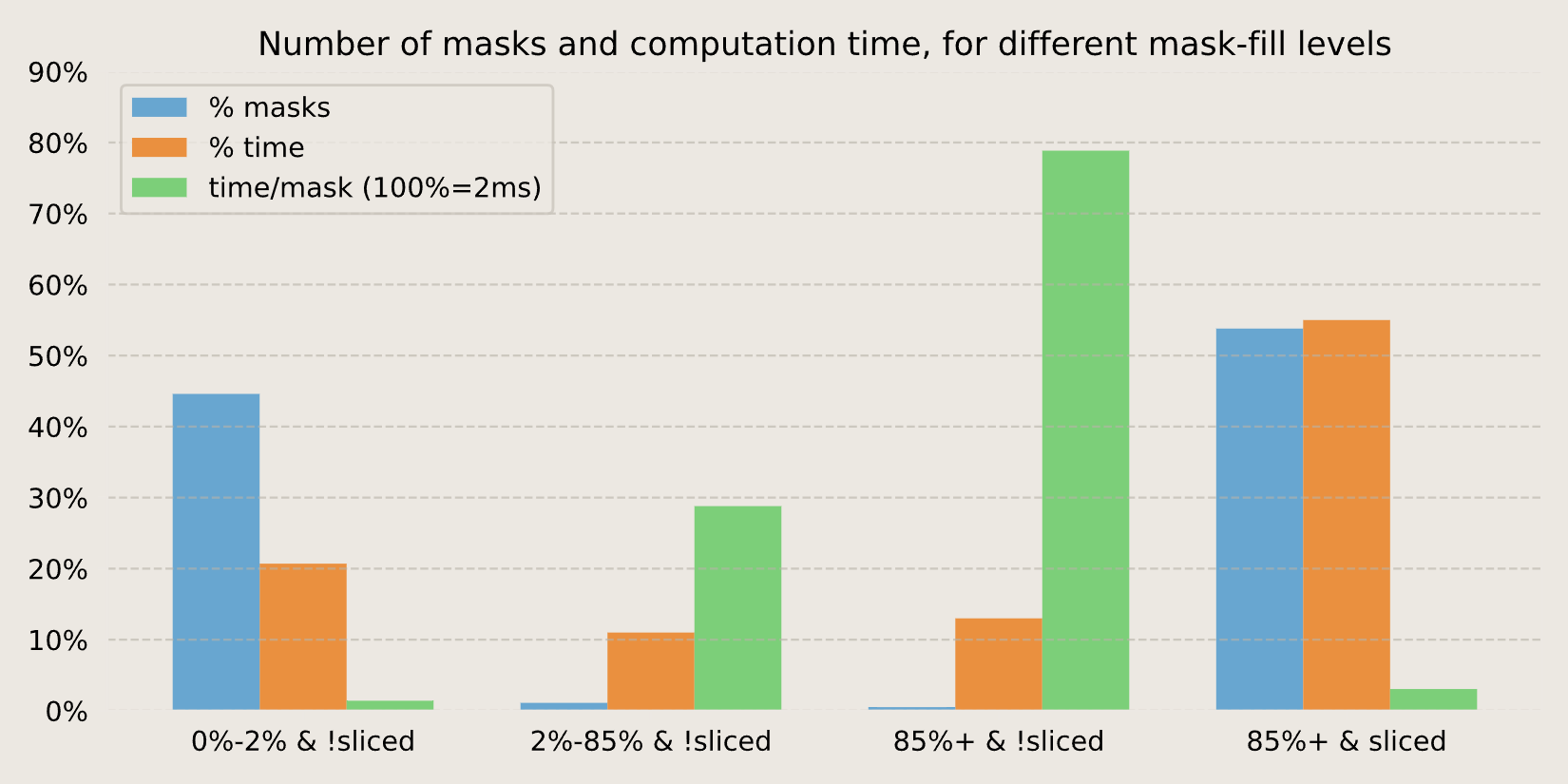
Dense mask 的痛點常在 JSON string。把字串用[^"\\\x00-\x1F\x7F]{1, N}這類 slice 表達,N 要實際設上限(像 10、30),Slicer 才吃得到甜頭。欄位規格化
數字、枚舉、日期、ID,盡量用正則與型別描述清楚。Sparse mask 越多,越省時。善用現成整合
LLGuidance 已在 Guidance、llama.cpp、Chromium、SGLang、vLLM、LLGTRT、mistral.rs、onnxruntime-genai 等專案使用。你若跑的是這些推論堆疊,幾乎不用自己造輪子。延遲預算分配
量測你那顆模型在目標 batch size 下單步 forward 的時間,確保 mask 計算 < forward。在 A100/ H100 世代,通常成立;真的卡住,優先檢查是否有超長自由字串沒加上限。逐步導入
先從最常壞掉的任務上 grammar (例如 tool calling 的參數 JSON),看錯誤率與 tail latency 的跌幅,再擴到 codegen/抽取。
我自己的判斷
結構化輸出已成「系統層責任」
從 OpenAI 把 Structured Outputs 切到 LLGuidance 背後,到各大推論框架內建 grammar support,這件事不再是 prompt/推運氣,不上 grammar,等於放棄 SLOSlicer 是工程上的勝負手
大多數系統卡在「看似自由、其實可界定」的內容 (字串、註解、模板),Slicer 讓你用幾條規則把大塊密集區域變快,這不是理論上的炫技,是實際的尾延遲保險,需多考慮。與 RAG/Agent 的組合會更重要
工具調用、結構化檢索結果、函式序列的中繼資料,都需要語法保證;LLGuidance 讓這些 agent 流程在吞吐與一致性上更像「系統」而不是「demo」。
作者:ZhihaoLab