使用 LM Studio 執行 gemma-3-4B-T1-it
使用 LM Studio 執行 gemma-3-4B-T1-it
完整的新手教學:在你的電腦上執行 Twinkle AI 的繁體中文語言模型。

圖1. 模型封面
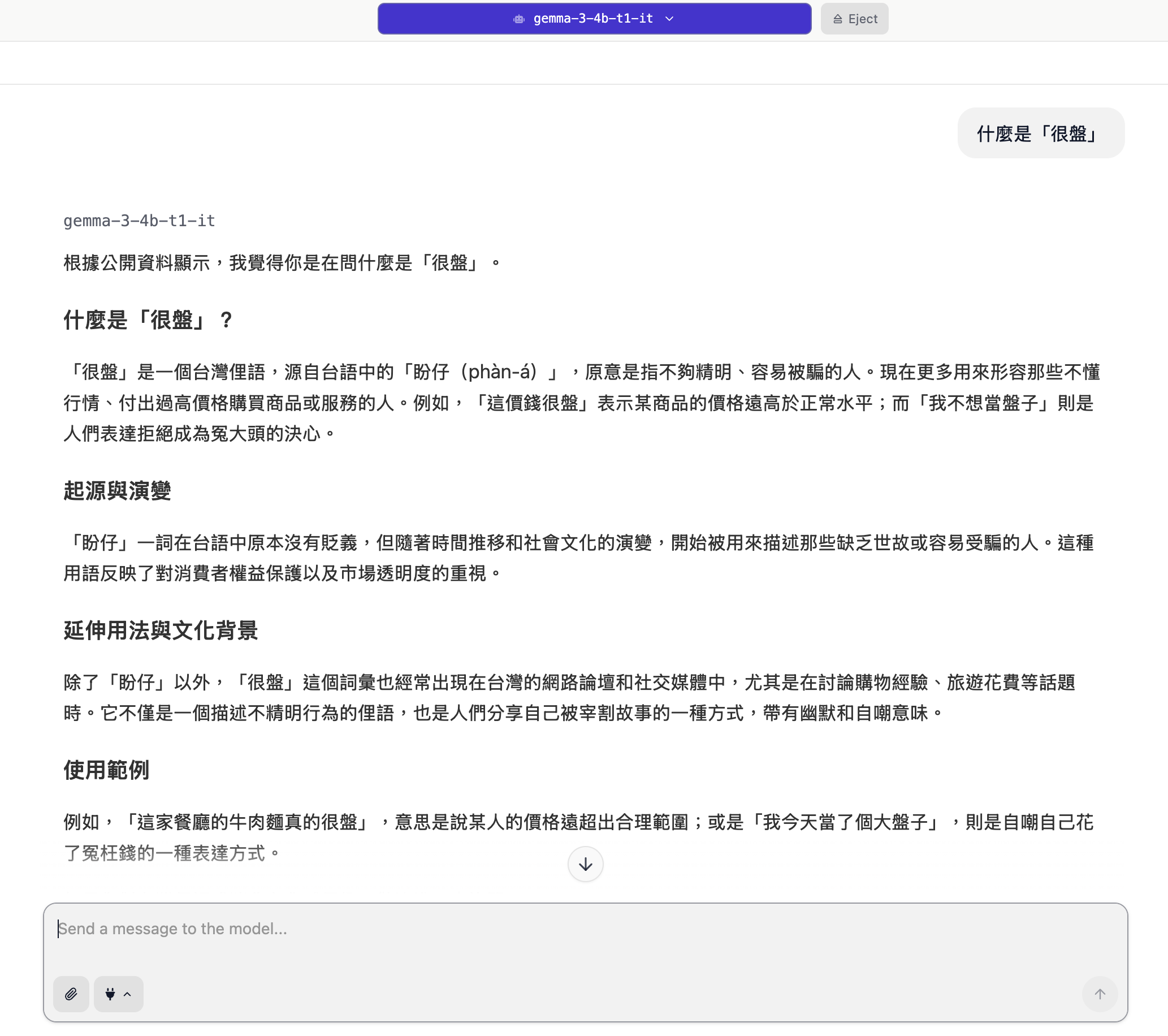
圖2. 模型執行示意圖(1)
這是一份關於「使用 LM Studio 執行 gemma-3-4B-T1-it」的簡短摘要(TL;DR):
核心重點
工具:使用 LM Studio 桌面應用程式,在電腦上離線執行 AI,具備高度隱私且完全免費。
模型:選用 gemma-3-4B-T1-it,這是一款專為繁體中文優化的輕量化模型,適合一般筆電執行。
系統需求
記憶體:至少 8GB(建議 16GB 以上)。
硬體:支援 Windows、macOS 與 Linux;有 NVIDIA 顯卡或 Mac M 系列晶片效能更佳。
快速操作步驟
下載:前往 lmstudio.ai 下載並安裝軟體。
搜尋:在軟體內搜尋
thliang01/gemma-3-4B-T1-it-GGUF。下載模型:新手建議選擇 Q4_K_M 版本(平衡效能與大小)。
對話:載入模型後,即可用繁體中文開始聊天。
優化小秘訣
如果回應太慢,可開啟右側設定中的 「GPU Offload」(需有 NVIDIA 顯卡)。
若想確保回答品質,可在 System Prompt 加入指令,要求 AI 必須使用繁體中文回答。
📖 目錄
什麼是 LM Studio?
為什麼要使用此模型?
模型資訊
系統需求與硬體建議
完整操作步驟(下載、安裝、載入)
開始對話與參數設定
常見問題與效能優化
1. 什麼是 LM Studio?
圖3. LM Studio 官網
LM Studio 是一個免費、易用的桌面應用程式,讓你可以直接在自己的電腦上下載、安裝並執行大型語言模型(LLMs)。 不需要寫程式,就像安裝一般軟體一樣簡單!
🌟 主要特色
完全離線:斷網也能跑 AI,資料不出門。
隱私優先:所有對話紀錄都只存在你的電腦硬碟裡。
跨平台支援:Windows、macOS、Linux 通通能用。
免費使用:完全開源免費。
2. 為什麼選擇 gemma-3-4B-T1-it?
這款模型特別適合台灣使用者,原因如下:
🇹🇼 繁體中文優化:專為繁體中文語境訓練,講話不彆扭。
🚀 輕量高效:40 億參數(4B)的小型模型,一般筆電也能順暢執行。
🔒 隱私保護:適合處理機密文件或私人對話。
💻 低門檻:不需要昂貴的顯卡,用 CPU 也能跑(雖然慢一點)。
3. 模型資訊
模型:gemma-3-4B-T1-it
開發者:Twinkle AI 社群
基礎模型:Google Gemma 3(40 億參數)
專長:繁體中文對話與指令遵循
授權:Gemma 授權
連結:
GGUF 版本:https://huggingface.co/thliang01/gemma-3-4B-T1-it-GGUF
⚠️ 規格重點: 本模型為 純文本單模態(Single Modality)版本。
4. 系統需求
在開始之前,請確認你的電腦是否符合以下需求:
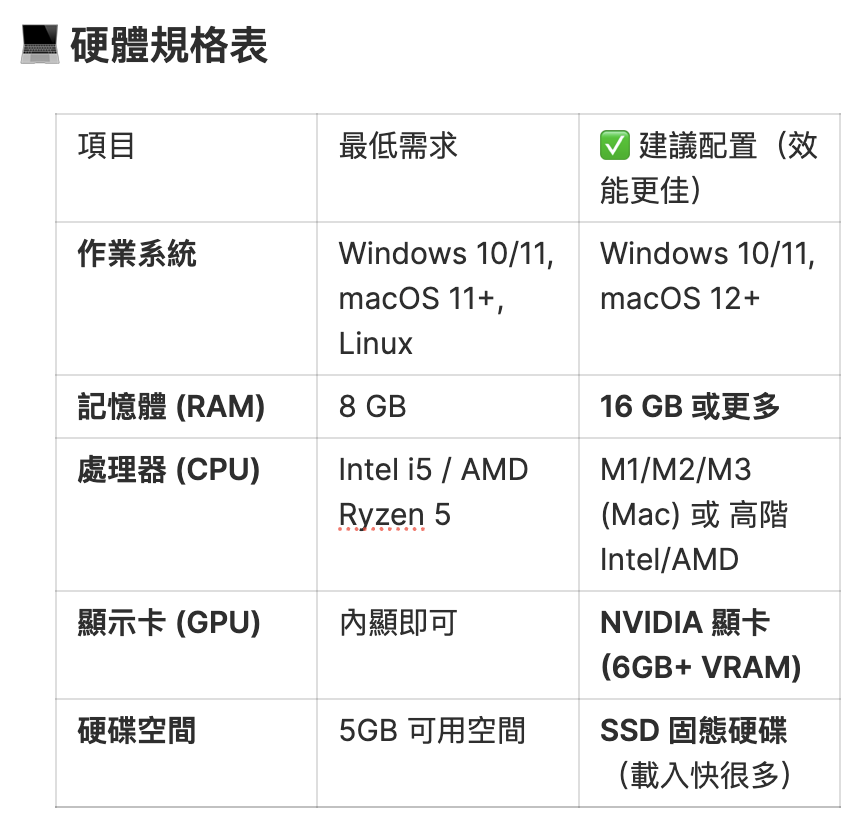
圖4. 硬體規格表
5. 完整操作步驟
步驟 1:下載 LM Studio
開啟瀏覽器前往官網:https://lmstudio.ai/
點擊首頁的 「Download LM Studio」 按鈕。
選擇對應你系統的版本(Windows .exe / macOS .dmg / Linux .AppImage)。
步驟 2:安裝軟體
Windows:雙擊
.exe檔,依照指示按「下一步」即可完成。
macOS:打開
.dmg檔,將 LM Studio 拖曳到「應用程式」資料夾。⚠️ 注意:若出現安全性警告,請至「系統偏好設定」→「安全性與隱私權」點擊「強制打開」。
步驟 3:下載 gemma-3-4B-T1-it 模型
這一步最關鍵!請跟著做:
開啟搜尋功能:點擊右側邊欄的「放大鏡」圖示(Discover)。
圖4. 開啟搜尋功能
輸入關鍵字:在搜尋欄輸入
thliang01/gemma-3-4B-T1-it-GGUF並按下 Enter。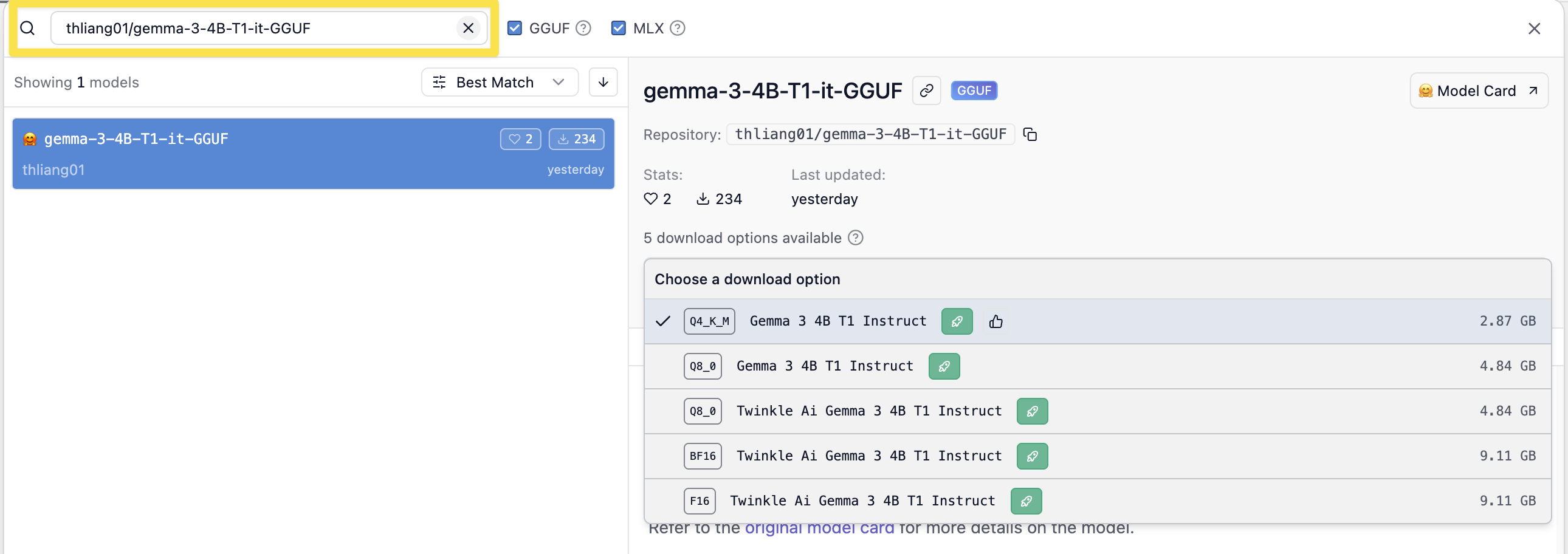
圖5. 輸入關鍵字
選擇並下載模型:你會看到右側出現多個檔案,請參考下表選擇:
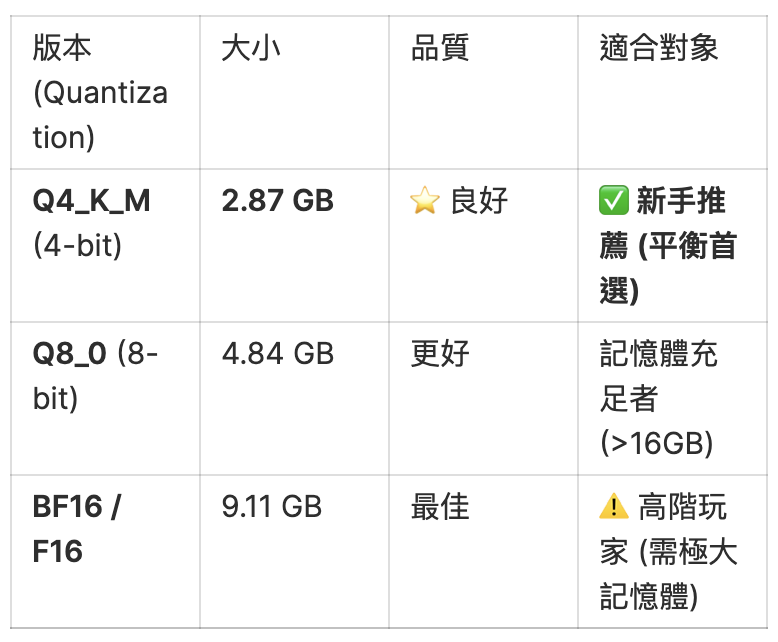
圖6. 選擇並下載模型
ℹ️ 小撇步:點擊該版本右側的 「Download」 按鈕即可開始下載。請耐心等待進度條跑完。
步驟 4:載入模型
點擊左側邊欄的 「對話框圖示」(Chat)。
在上方中間的選單點擊 「Select a model to load」。
選擇剛剛下載的
gemma-3-4B-T1-it。
上方會出現綠色條顯示載入進度,直到看見
Model loaded字樣。
6. 開始對話與參數設定
現在你可以用繁體中文跟它聊天了!試著輸入:「你好!請介紹一下台灣的夜市文化。」
圖7. 模型執行示意圖(2)
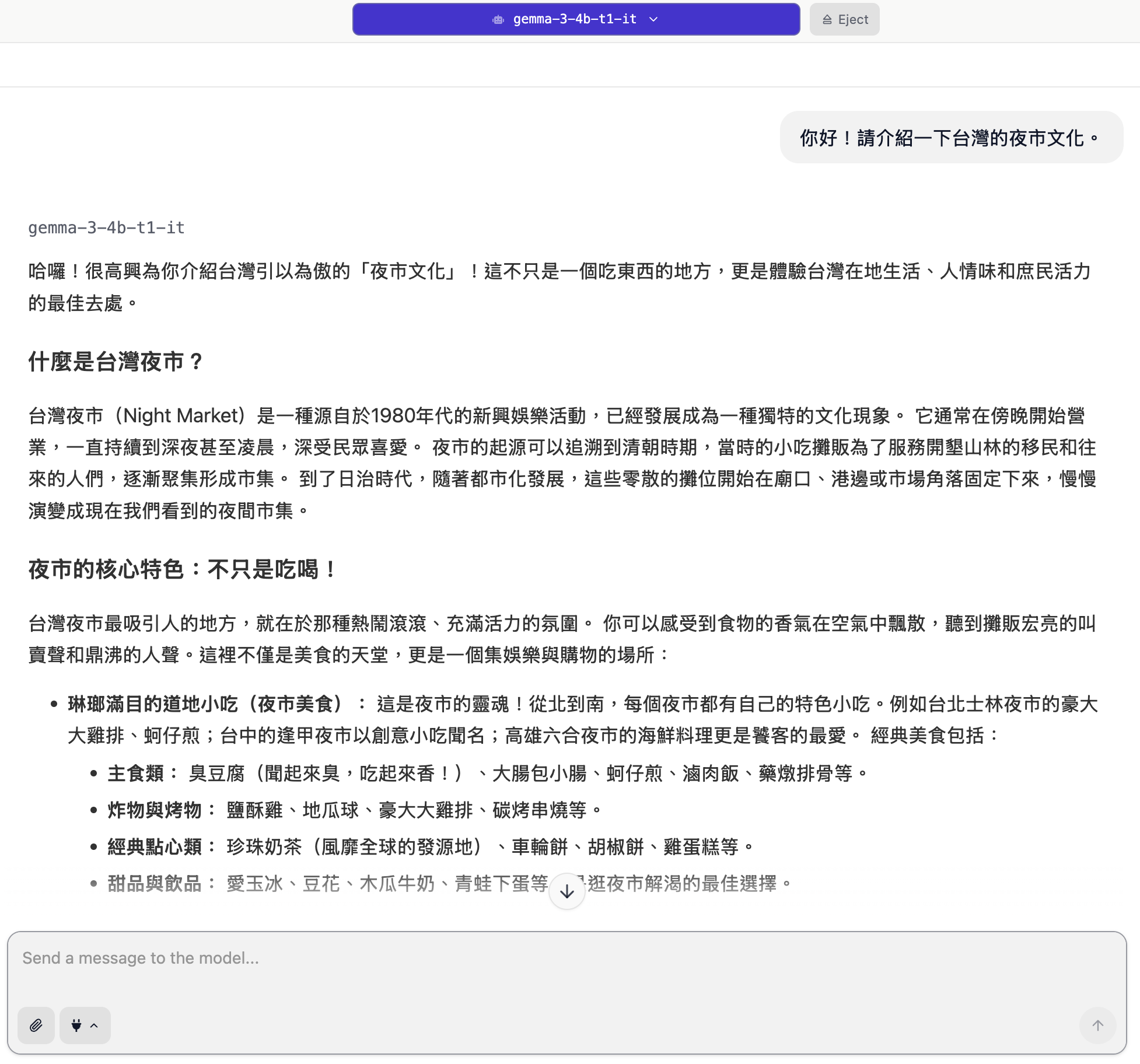
圖8. 模型執行示意圖(3)
💡 進階技巧:設定系統提示 (System Prompt)
如果模型突然講英文,或是回答不夠精確,可以點擊聊天視窗上方的 「Add instructions」 區域,輸入以下指令來「催眠」它:
「你是一個專業且中立的繁體中文 AI 助手。請用繁體中文回答所有問題,提供準確、詳細的資訊。」
這樣能大幅提升回答的穩定度!
7. 常見問題與疑難排解 (Troubleshooting)
⚠️ 問題:顯示「記憶體不足 (Out of Memory)」
解法:請改下載 Q4_K_M 版本(檔案較小),並關閉瀏覽器或其他耗資源的軟體。
⚠️ 問題:回應速度很慢 (1字/秒)
解法 1:這是因為正在使用 CPU 運算。若你有 NVIDIA 顯卡,請到右側設定開啟 「GPU Offload」,將滑桿拉到最大,並點擊
Reload Model。
解法 2:縮短 Context Length(例如降到 2048)。
⚠️ 問題:回答出現亂碼或英文
解法:確認你在系統提示 (System Prompt) 中已強調「使用繁體中文」,並將 Temperature 稍微調低至 0.5 試試。
🎉 恭喜! 你已經成功在自己的電腦上架設了專屬的繁體中文 AI。現在,享受安全、私密且無限暢聊的 AI 體驗吧!
🤝 加入社群
如果你覺得 gemma-3-4B-T1-it 對你有幫助,歡迎加入 Twinkle AI 社群,與其他開發者、研究者和使用者一起推動繁體中文 AI 模型的發展!
加入 Twinkle AI Discord:https://discord.gg/gHas8jdr
作者:Thomas