從 Tags 到 LLM Wiki:知識管理工具的演進與下一個挑戰
探討知識相關類型的產品大概一年多了,從 AILogora 一路做到現在的 Cairn,我其實一直在想同一個問題:知識到底要怎麼被組織、被找到、被重複利用?
我是筆記產品的愛好者,過去我用過 Notion、Obsidian、試過空間化的整理方式、也用 LLM 把資訊轉成 Wiki 再結合 Vector。最近 Karpathy 的 LLM Wiki 在社群上爆了,我覺得是個好時機,把我目前對這個領域的理解整理出來,算是是實際踩過坑之後的觀察,也請大家不吝指教。
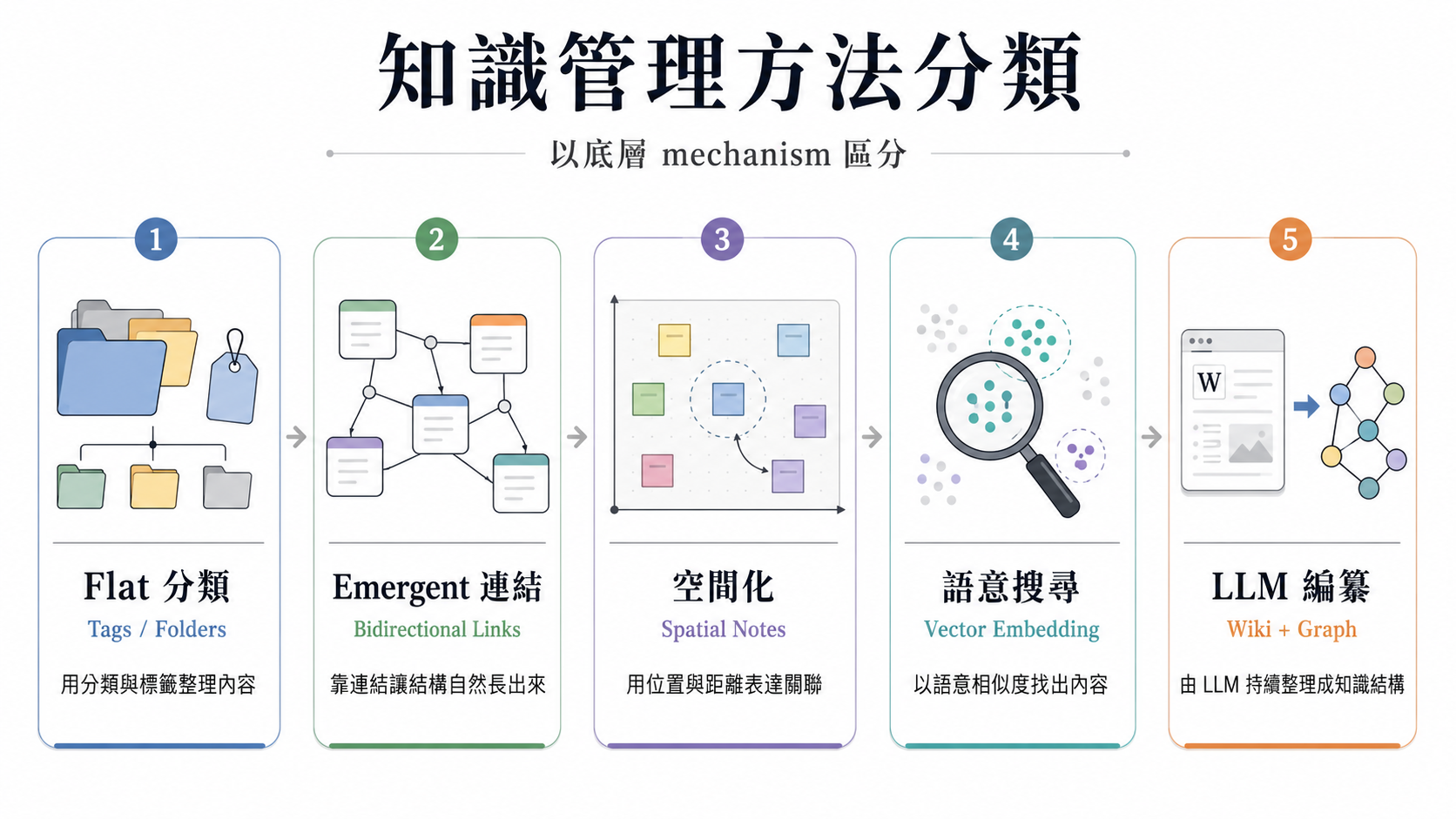
先從方法本身講起,我這邊是用底層 mechanism 來分的,不是用「給個人還是給企業」來分,因為知識怎麼被處理不應該因為人數不同而改變。
1. Flat 分類:Tags / Folders
最傳統的方式。Notion、Apple Notes、Bear,包括企業用的 SharePoint、Confluence,底層邏輯其實都一樣,把東西丟進分類、打標籤、設權限。企業 KM 只是多包了一層版本管理和合規功能,骨子裡還是 flat 的。
Tiago Forte 的 PARA(Projects / Areas / Resources / Archives)算是這條線做到最極致的方法論了。不過他今年自己也推了「AI Second Brain」的課程,這代表連現在最硬核的 Second Brain 社群都開始轉向 AI-assisted 的組織方式了。
問題大家都知道:東西一多就找不到,一篇筆記到底該放「AI」還是「產品設計」,放哪邊都不完全對。
2. Emergent 連結:Bidirectional Links
2020 年 Roam Research 帶起的風潮,每張卡片用 [[link]] 互相連結,不預設分類,讓結構自己長出來。Obsidian、Logseq 也是這條線。
我自己用過一陣子 Obsidian,體感是筆記超過幾百張之後 graph view 就變成一團毛線球。你看得到連結但看不到什麼是重要的,所有東西在視覺上都一樣大。Roam 2020 年爆紅,但後來聲量明顯被 Obsidian、Tana、Heptabase 分散,我自己也是 2020 年用過 3個月左右,Roam 確實戴起了這波風潮,但卻沒站穩滿可惜的,反倒是 Obsidian 靠本地 Markdown 加插件生態站得更穩了。
3. 空間化:Spatial Notes
Heptabase 是代表,台灣團隊做的,我也用過幾個月。核心概念是把筆記放在無限白板上,用位置表達關聯。不靠連結,靠「你把什麼東西放在旁邊」。
老實說,在處理那種「還不知道怎麼分類」的破碎資訊時,白板的視覺化優勢真的很強。你可以很直覺地看出哪些概念是一組的,非常適合用來做前期的 sense-making 或架構發想。這個我在 AILogora 試過,拿來初步整理主題的時候的確很好用。
不過 scale 上去之後還是會碰到瓶頸。當白板越長越大,你最後還是會需要某種「地圖」去告訴你什麼東西在哪裡。
4. 語意搜尋:Vector Embedding
Mem.ai、Notion AI、ChatGPT memory,還有企業端的 Glean。把所有內容轉成 vector,靠語意相似度搜尋。不用分類不用連結,丟進去就好。Glean 做得比較進階,底層有 knowledge graph 加 hybrid search(vector + keyword),還有 permission-aware 的機制。
Hybrid search 確實改善了 retrieval 的品質,但它通常還是沒有把 disagreement、authorship、claim 跟 evidence 之間的關係變成使用者可以導航的知識結構。搜尋變準了,但你看到的還是一堆「最相關的段落」,不是一張有脈絡的 map。
5. LLM 編纂:Wiki + Graph
這是最新的一條線。Karpathy 今年四月在 X 上發了 LLM Wiki 的概念,1600 萬觀看,GitHub Gist 幾天 5000 星。
三層架構:Raw(原始資料不動)、Wiki(LLM 生成的 Markdown 頁面)、Schema(一份 CLAUDE. md 定義維護規則)。LLM 不是拿來問答(那是 RAG),是拿來持續編纂的。每次餵新資料,它自動更新十幾頁 wiki,好的問答結果可以回寫成新頁面。
我們在 AILogora 也獨立走到了類似的方向,用 LLM 把社群裡的資訊整理成 Wiki,再結合 Vector 做搜尋。做了之後發現一件事:LLM Wiki 產出的 Knowledge Graph 跟 Obsidian 的 graph view 或 VectorDB 畫出來的圖完全不同。Obsidian 的 graph 是「誰連了誰」,VectorDB 的 graph 是「誰跟誰相似」,兩種畫出來可讀性都很低。但 LLM Wiki 的 graph 是有語意層級的,頁面之間的關聯是「這個概念屬於那個主題」「這個證據支持那個論點」,結構本身有意義。
這個方向我覺得是對的。
但這裡有一個我覺得更深的問題
不是所有知識管理工具都明講 Single Source of Truth(SSOT),但大多數工具都有一個共同的限制:它們很擅長保存內容,卻不擅長保存「觀點之間的形狀」。
一篇文章可以被放進 folder,一張卡片可以被 link 到另一張卡片,一段文字可以被 vector search 找出來,一個 LLM 可以把十份資料整理成一篇 wiki。可是當三個人說「RAG 很有效」,另一個人說「RAG 在我這裡一直 hallucinate」,系統通常只能做三件事:把它們平均成一個結論、挑一個最新版本、或把它們當成幾段相似文字。
但真正有價值的往往不在平均出來的結論,反倒是這個 disagreement 的 shape:誰在什麼 context 下成功,誰在什麼條件下失敗,哪些 evidence 支持哪個 claim。SOP 和 API 文件當然需要唯一正確版本,但一個人的實測經驗跟另一個人的實測經驗,本來就不該被壓成同一個結論。
Wikipedia 在這件事上其實做得比大多數工具好,它的 NPOV 政策是按來源顯著性比例呈現主要觀點,不是單純壓成一個版本。但它還是把多觀點整理進一篇 editorially governed 的文章裡,每個觀點的 authorship、context、evidence relation 在這個過程中被抹平了。
Mem0 的 memory 機制也是,當事實衝突時自動覆寫舊版本。Karpathy 的 LLM Wiki 因為是個人工具,自然只留下一個視角的整理。
當然認為 SSOT 有限制的不只是我,資料工程圈已經有人在反思了,有篇文章直接叫「Single Source of Truth — A Modern Data Myth?」,PLM 領域今年也有人寫「SSOT 從來不是最終答案」。他們的觀察是,不同部門對同一個產品的數據有不同的合理視角,硬是要壓成一個版本反而失真。他們提出的替代概念蠻有意思的:與其死守 single source of truth,不如改成 single source of change。也就是保留一個統一做決策和傳播的控制點,但允許數據本身活在多個地方。
哲學上也有對應的框架叫 Epistemological Pluralism(知識論多元主義),主張不同類型的知識可能需要不同的認知架構。這邊連 Wikipedia 自己的 SSOT 條目都承認:SSOT 依賴一個本體論假設,就是「對任何特定事實,只存在一個真相」。
這些批評目前散落在資料工程和哲學裡,還沒有人把它帶進 knowledge management 的產品設計。
如果知識天生有多個面向,系統要怎麼設計?
在其他領域已經有一些嘗試。學術界有 Discourse Graphs(Protocol Labs 推的),把研究拆成 claim、evidence、question 這些原子級元素,用 graph 表達支持和反駁的關係,保留 authorship。台灣的 vTaiwan 用 Polis 做大規模意見映射,不追求共識,而是找出意見的結構。
但前者侷限在學術圈,後者處理的是 opinion 而不是結構化的知識。在一般的技術社群或產品團隊裡,目前還沒有人把這幾個元素組合在一起做成產品。
這也是我從 AILogora 一路走到 Cairn 的背景。
AILogora 原本是用卡片加收藏牆的邏輯在做知識策展,有點像 Are. na 那種模式,讓每張卡片可以被放到不同的收藏牆裡。跑了一陣子之後覺得 AI 的部分可以切得更深,剛好有個 Hackathon 的機會,就把其中跟 LLM 知識整理相關的那塊拉出來快速迭代,變成了 Cairn。
在 AILogora 我們已經驗證了 LLM → Wiki 這個方向跑得通,但碰到一個問題:當不同人對同一件事有不同經驗的時候,Wiki 只能呈現一個整理過的版本,其他觀點就被吃掉了。其實我們真正需要的,早就不只是單一的 single source of truth 了,我們更需要一張能看見多元觀點和彼此之間關聯的 map。
所以 Cairn 不是要做另一個 AI Wiki,也不是 Mem0 那種幫 LLM 記住一個 user 的 memory layer。我們在做的是一個能讓多個 contextual truth 共存、保留它們之間關係的 memory layer。
具體來說,我們把 MOC(Map of Content)這個 PKM 圈用了很多年的概念重新定義:
atom 是個人的經驗或觀點,一個人寫、一個人負責,帶 authorship 和 context
L1 MOC 是 topic-level 的結構,「這幾個 atom 在回答同一個問題」
L2 MOC 是 theme-level 的結構,「這個社群關心哪幾個大方向」
LLM(我們叫 Moss)草擬 MOC,但人來決定「哪些東西該放在一起」
這套機制不只是給社群用的。個人用的時候,它就是 Karpathy 的 LLM Wiki(Schema → Wiki → Raw)。團隊用的時候,它比 Confluence 多了「結構是 AI 維護的、人審核的」。社群用的時候,它能保留 disagreement 的 shape 而不是壓成共識。
這個 thesis 也可能是錯的。也許多數人不需要看見 disagreement 的 shape,他們只是想要更好的搜尋、更可靠的摘要、更低摩擦的 wiki。Cairn 真正想驗證的核心挑戰在於:「在什麼場景下,保留 disagreement 真的能改變決策品質?」這遠比單純證明「多觀點很浪漫、很美」來得有意義。
目前我們的 MOC-gated retrieval 有跑出一些不錯的 eval 數據(Moss 對比 ChatGPT 和 Perplexity 在結構化回答上有明顯差距),但社群規模的驗證還沒做完。資料工程圈在講 single source of change,我們在試的是用 MOC 做 single source of structure,讓多個 truth 共存但有結構可循。
寫這篇的時候把過去一年多的東西重新梳理了一遍,才發現 Cairn 現在在做的很多事情,真的是沒有 AILogora 那段經驗就過不來的。Tags 試過了、空間化試過了、LLM → Wiki 也試過了,每一種都有學到東西,但也都碰到了天花板。那些天花板最後指向了同一個方向,就是知識管理這個問題比我一開始想的複雜太多,不是換一個工具或換一種分類法就能解決的。
也不確定 Cairn 走的方向最後會不會對。但至少現在回頭看,這一年多沒有白繞。😅
如果你也在研究類似的題目,Karpathy 的 LLM Wiki Gist、Protocol Labs 的 Discourse Graphs、vTaiwan 的 Polis 案例都蠻值得看的,Cairn 這周也會找早期試用者,歡迎來聊聊。
作者:Chi