Universal Reasoning Model
最近在看一篇叫 Universal Reasoning Model 的 paper,感覺蠻值得做產品的人看,這篇在講現在習慣的大模型,其實在「推理」這件事上,可能真的不是最有效率的那個選擇。
這篇工作是站在 Universal Transformer(那個把 Transformer「打成一層,然後反覆 loop」的架構)上,作者先把幾個近期在 ARC-AGI、數獨上表現很好的 loop 型模型拆開來驗屍,結論有點出乎意料,很多人以為贏在 fancy 的層級設計、gating 機制,結果實驗看起來,真正重要的是兩件事,反覆疊同一個 layer 的「循環歸納偏好」,跟模型裡那一坨很強的非線性。
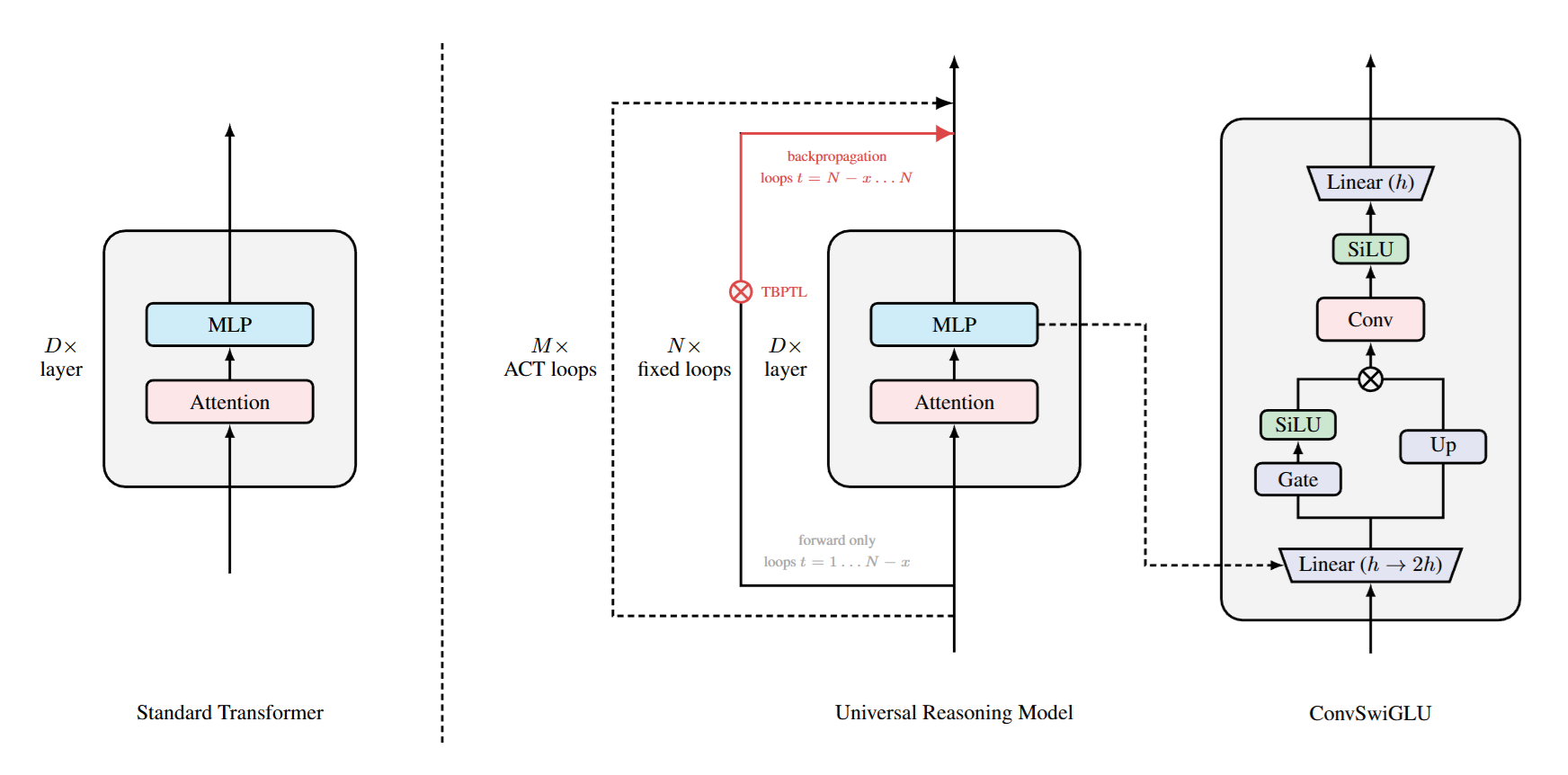
他們提了一個叫 Universal Reasoning Model(URM)的版本,基本上是用 decoder-only 的 Universal Transformer,然後在 FFN 裡加一個短卷積版的 SwiGLU(ConvSwiGLU),再配上一個很 RNN 風格的「Truncated Backpropagation Through Loops」,前幾個 loop 只 forward、不回傳梯度。
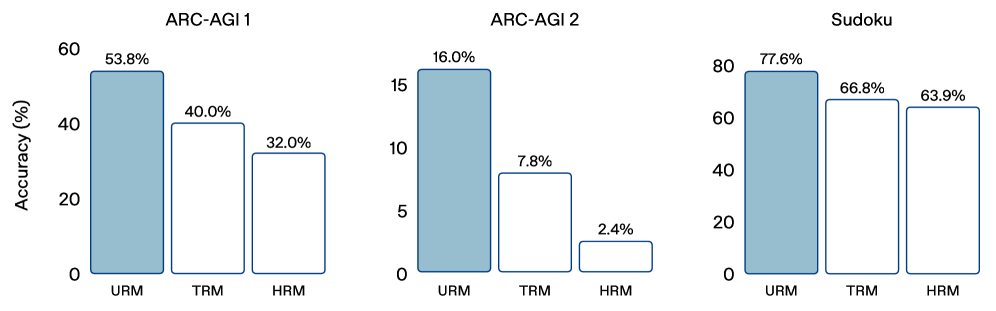
有趣的是這樣一個看起來沒那麼花俏的改動,在 ARC-AGI 1 上可以做到 53.8% pass@1、ARC-AGI 2 做到 16.0%,都是目前這條線上很前面、而且遠超不少大參數 LLM 的數字。
裡面幾個點記下來:
第一,作者把 vanilla Transformer 跟 Universal Transformer 在參數量、FLOPs 固定的情況下逐格對比,結果是:在相同或更少的參數與算力下,UT 一路輾壓,尤其是像 ARC-AGI 這種需要多步抽象的任務。
第二,他們專門做了一大組消融,只動「非線性」這個維度,把 SwiGLU 換成 SiLU、再換成 ReLU,或是乾脆把 attention 的 softmax 拿掉,表現就是一路崩;反過來,強化 FFN + 短卷積的非線性,分數就穩穩往上爬。
還有一個很工程感的設計是 TBPTL,如果你對 RNN 的 TBPTT 有印象,這個東西概念幾乎一樣,把很多 inner loop 的 recurrent 推理拆成「前面只 forward、後面才真的算梯度」,避免整條鏈的梯度噪音把訓練搞到不穩定。
他們實驗固定 8 個 inner loop,掃不同的「有梯度 / 沒梯度」切分點,結果是前兩圈只 forward、後 6 圈回傳梯度會最好,再長或再短都變爛,這種「中間點最好」的形狀,跟以前在 RNN 上看到的現象蠻像的。
如果用做產品的角度來看,這篇給我的提醒有幾個:
一是,不要再單純往「更大、更深的 Transformer」堆,對需要多步推理的任務,重複使用同一層、讓模型自己在內部反覆 refine 表徵,其實在參數效率跟 FLOPs 效益上都更健康。
二是,那些看起來很「小」的 architectural 決定——比如 activation 用什麼、MLP 裡要不要加一點 local conv,在這類任務上,真的不是微調等級的小事,而是決定你是 20% 還是 50% pass@1 的關鍵槓桿。
最後,URM 還順手測了一下 Muon 這種二階感比較強的 optimizer,相對於 Adamatan2,可以明顯加快收斂速度,但最終收斂的成績差不多,對在玩 loop transformer 或 recurrent 架構的人來說,這其實是一個蠻實際的訊號,因為架構本身決定了你能不能學會那個推理,optimizer 決定你要花多少電費把它學完。
作者:林 Jay