Gemini 2.5 Flash 跟 Flash-Lite 出了
Google 今天釋出了新版的 Gemini 2.5 Flash 與 Flash-Lite 預覽模型,延續了「更快、更省、更聰明」的路線,這次的更新其實可以看出他們正嘗試把兩條產品線切得更清楚:
Lite 走的是高吞吐量、低成本場景
Flash 則是往智能化、多步驟推理與工具使用方向邁進
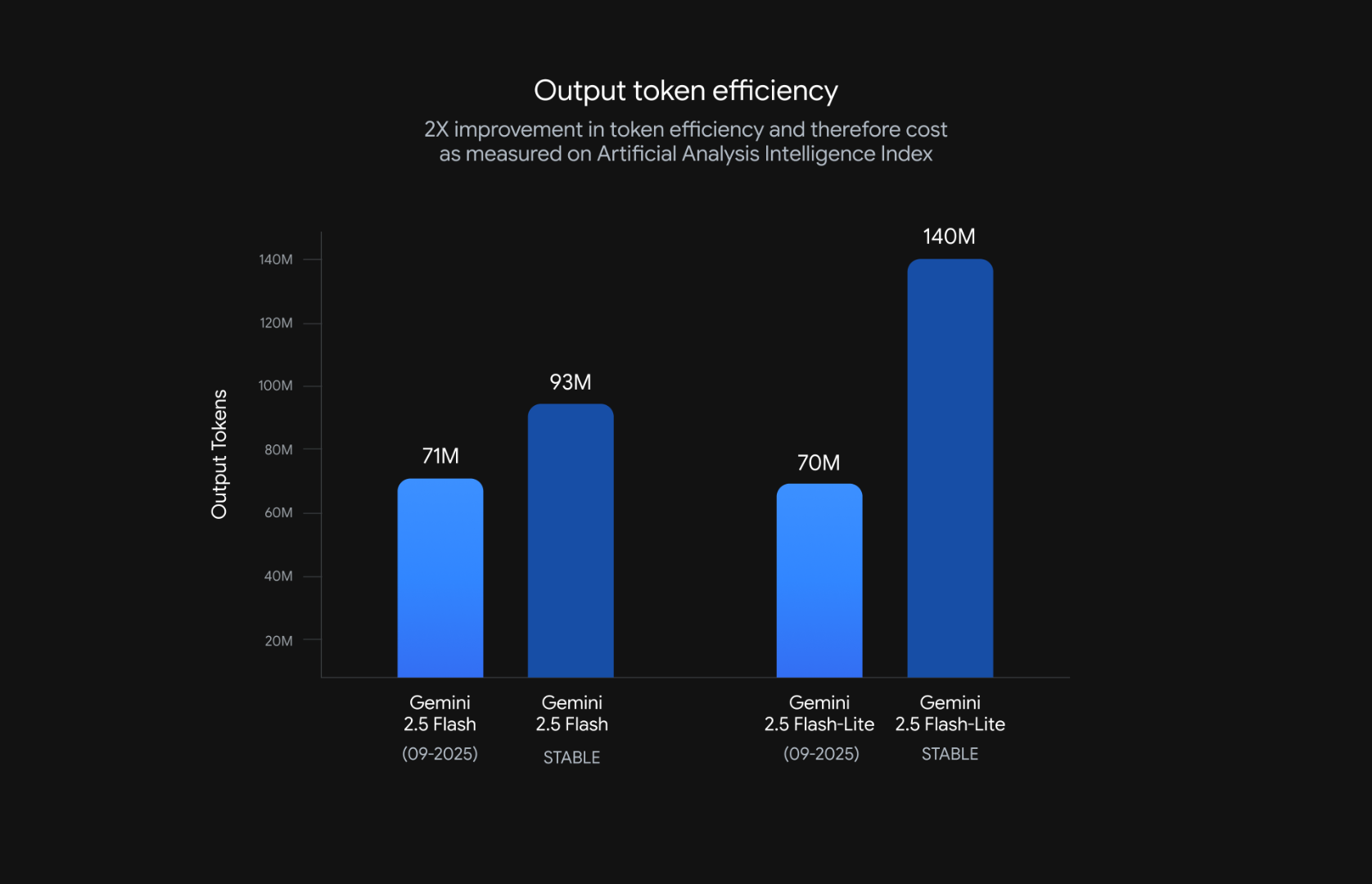
先看 Flash-Lite,新版模型在指令跟隨的能力明顯提升了,面對複雜的 prompt 或不規則的 system prompt 也能更貼近需求,同時它有意識地壓縮了輸出,讓回答更精簡,這對於高頻 API call 的應用來說,不只是延遲減少,token 成本也能顯著下降,大家應該會很喜歡。
Google 自己給的數據是輸出 token 整整減少了 50%,對於要跑大量客服、即時互動或聊天機器人的場景,這個數字應該很香,再加上語音轉錄、影像理解與翻譯品質的提升,可以想像它會更適合多模態的應用。
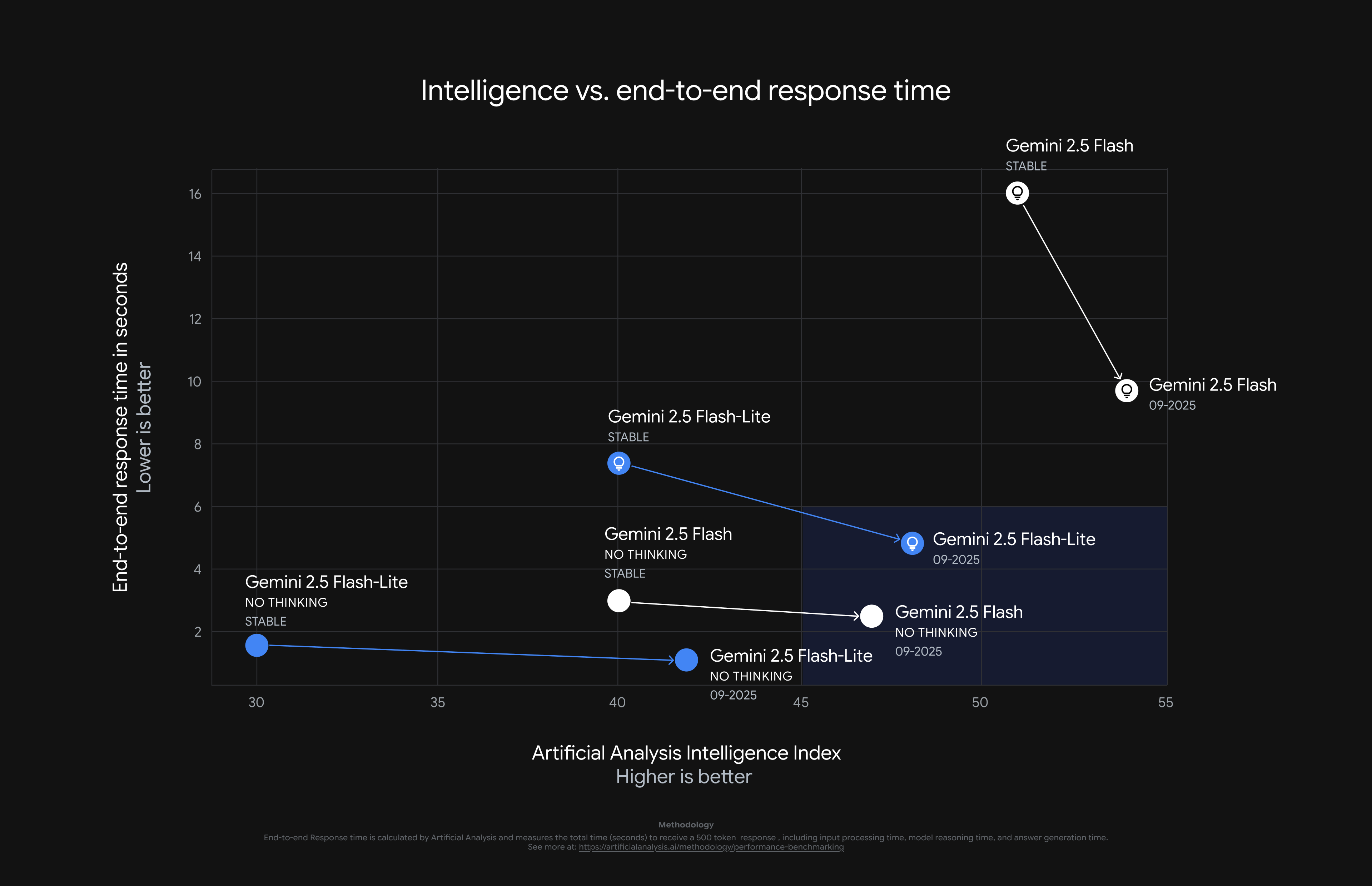
Flash 版本則是在另一個方向進化,Google 收到的最大回饋是「Agent 工具使用」還不夠好,這次的更新就集中火力處理這點。新的 Flash 在多步推理與工具鏈場景中表現更穩定,像是在 SWE-Bench Verified 基準上就直接拉升到 54%,更重要的是在 thinking 模式下變得更省 token,也就是說品質上升的同時,成本和延遲卻下降了。
這對正在打造 AI Agent 的團隊來說,這不只是 benchmark 分數漂亮,而是能實際放大可運行的規模,Google 引述了 Manus 的科學長的說法:長任務情境下性能直接提升 15%,而且能以更低成本支撐更大規模,這點應該戳中不少團隊的痛點。
有團隊已經去試過了嗎? 現階段我們是不太好直接換模型,可能會在小專案上先嘗試。
作者:王志遠