The Big LLM Architecture Comparison
這篇 LLM 架構比較我覺得滿有參考價值,
裡面把不同模型的 backbone、positional encoding、activation function、normalization method、parallelism design 等,
整理成一張表如下:
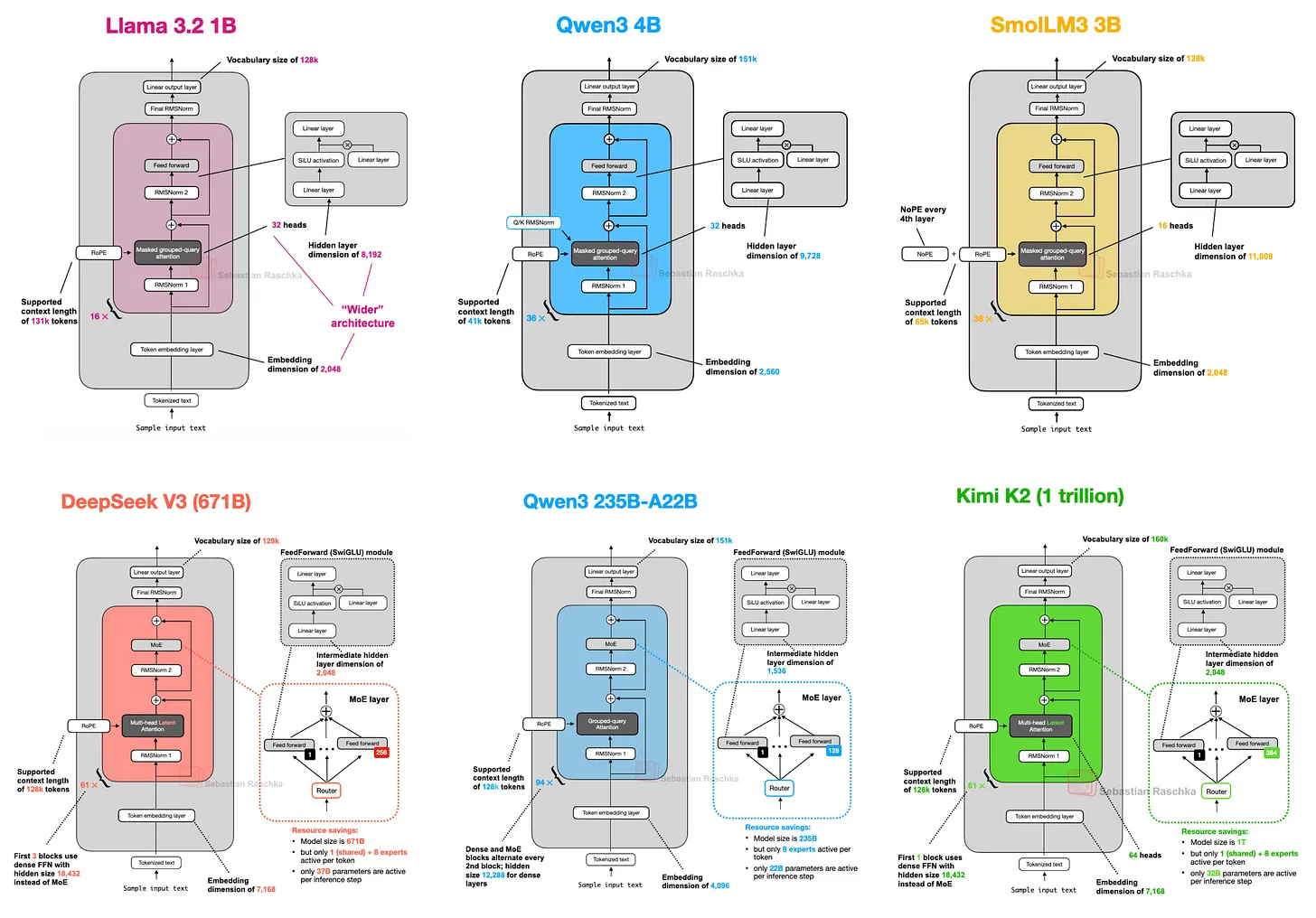
我自己看完有兩個感觸:
設計逐漸收斂:雖然大家有些微差異,但很多設計慢慢收斂,例如 SwiGLU 幾乎成了標配,RoPE 也是主流。
工程 vs 科研:很多設計差異,其實不是理論上誰比較好,而是誰在大規模 training 時能又穩又快,凸顯 LLM 的發展越來越像一個 engineering problem。
文章裡比較少談的是這些架構差異對 downstream tasks 的實際影響,
如一個模型選擇 RMSNorm 還是 LayerNorm,對 inference latency 或 fine-tuning stability 的影響,
不曉得有沒有人有實際比較,這對我們實作者來說更重要。
如果有在做模型訓練或部署的人,可以直接拿圖片當備忘錄,
至少知道各家在什麼地方做了不同取捨。
作者:早八晚十