Stas Beckman - AI 戰場生存指南:如何建立具備韌性的 ML 工程技能?
Stas Beckman - AI 戰場生存指南:如何建立具備韌性的 ML 工程技能?
韌性 = 方法論 × 人脈 × 筆記。
別追工具熱度、別信行銷 TFLOPS,建立基準測試兵器庫(運算、網路與儲存)。
「誰」比「什麼」重要——連結 PyTorch、DeepSpeed 核心專家。
宗教式寫開源筆記,這是展現思考方式的最佳名片。
AI 擅長模式匹配,但深度邏輯與系統工程是人類不可取代的優勢。
找到利基,走你自己的路。

GPU MODE: Lecture 90: Building resilient ML Engineering skills
韌性(Resilience)是工程師的核心競爭力

在 AI 技術日新月異、模型與演算法每週更新的今天,光靠追蹤 Twitter/X 是不夠的,那是一個會吞噬精力的黑洞。Stas Bekman 指出,真正的韌性來自於解決問題的過程與方法論,而不是僅僅掌握當下的新工具。
行銷數據 vs. 實際效能:不要迷信 TFLOPS

硬體廠商提供的規格(如 TFLOPS)往往是理論上的最大值,甚至會利用「稀疏性(Sparsity)」資料來將數值翻倍,但在真實運算中幾乎無法達成。
• 現實落差: 效能往往受限於記憶體頻寬(HBM)、通訊開銷(Network)及散熱降頻(Thermal Throttling)。
• 世代弔詭: 隨著硬體進化,運算力增長速度遠超記憶體頻寬,導致新一代 GPU 的「利用效率」反而可能下降。
建立你的基準測試(Benchmarking)「兵器庫」

面對昂貴的 GPU 租借費用,工程師必須建立嚴謹的測試流程,針對三個領域進行「孤立測試」:

• 運算加速器(Accelerators): 針對你模型中實際的矩陣形狀(Shapes)測試真實 TFLOPS,這才是你該追求的「100% 基準」。
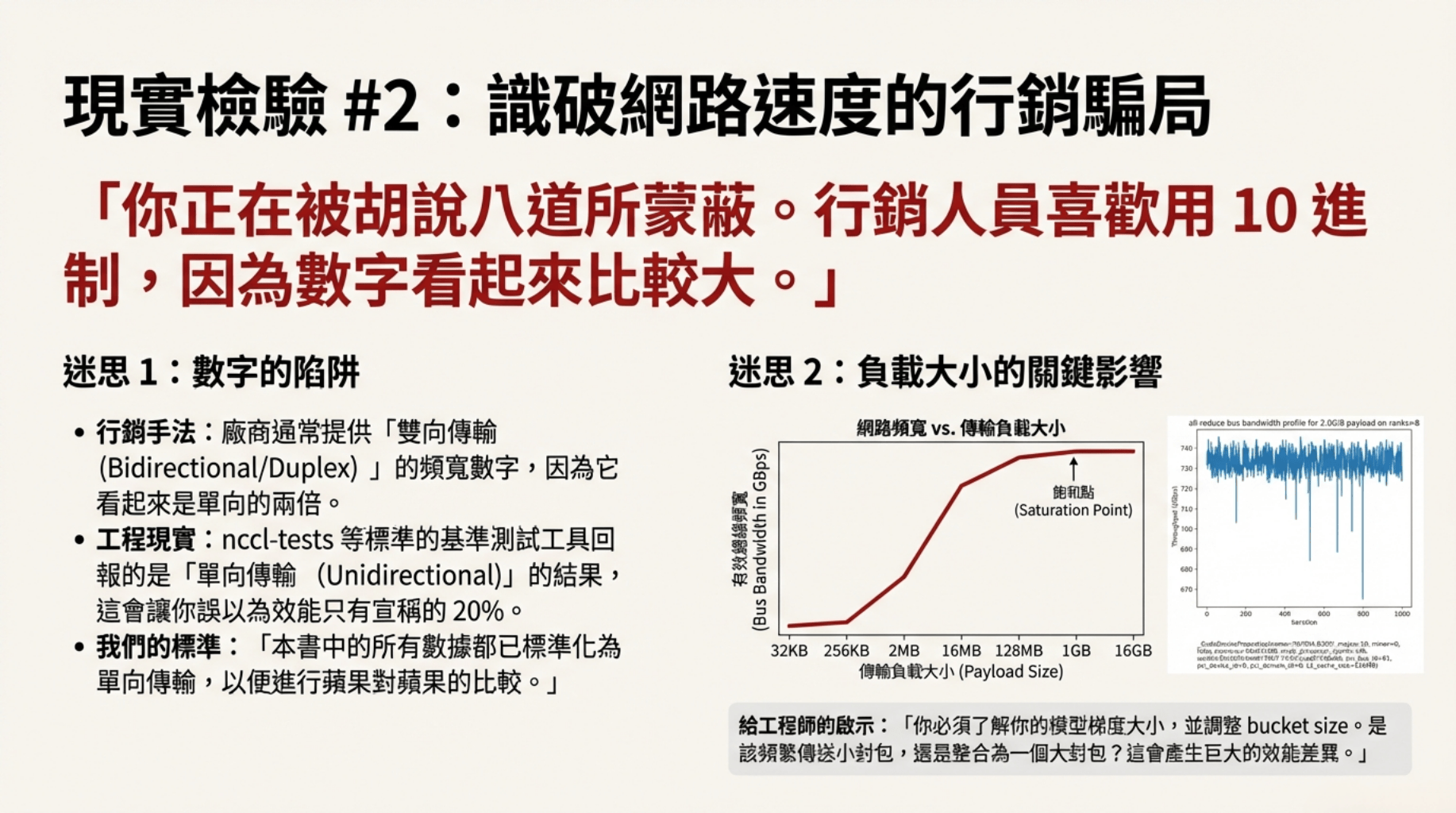
• 網絡互連(Networking): 不要看行銷標榜的 Duplex 頻寬,要測單向(Unidirectional)吞吐量。當通訊無法與運算重疊(Overlap)時,昂貴的 GPU 就會處於閒置狀態。

• 儲存系統(Storage): 這是最常被忽視的瓶頸。大量的小檔案(如 Python 套件或 Conda 環境)會讓共享檔案系統崩潰。
「誰」比「什麼」更重要:人際網絡的力量
Stas 分享在領導 BLOOM-176B 大型模型訓練時,他並沒有訓練數百個 GPU 的經驗。
• 成功的關鍵: 確保能接觸到 PyTorch、DeepSpeed 和 Megatron 的核心專家。
• 韌性連結: 在不斷變化的領域中,擁有能共同解決複雜系統問題的「人脈」是不可替代的資產。
對抗資訊碎片化:撰寫你的個人「開源筆記」
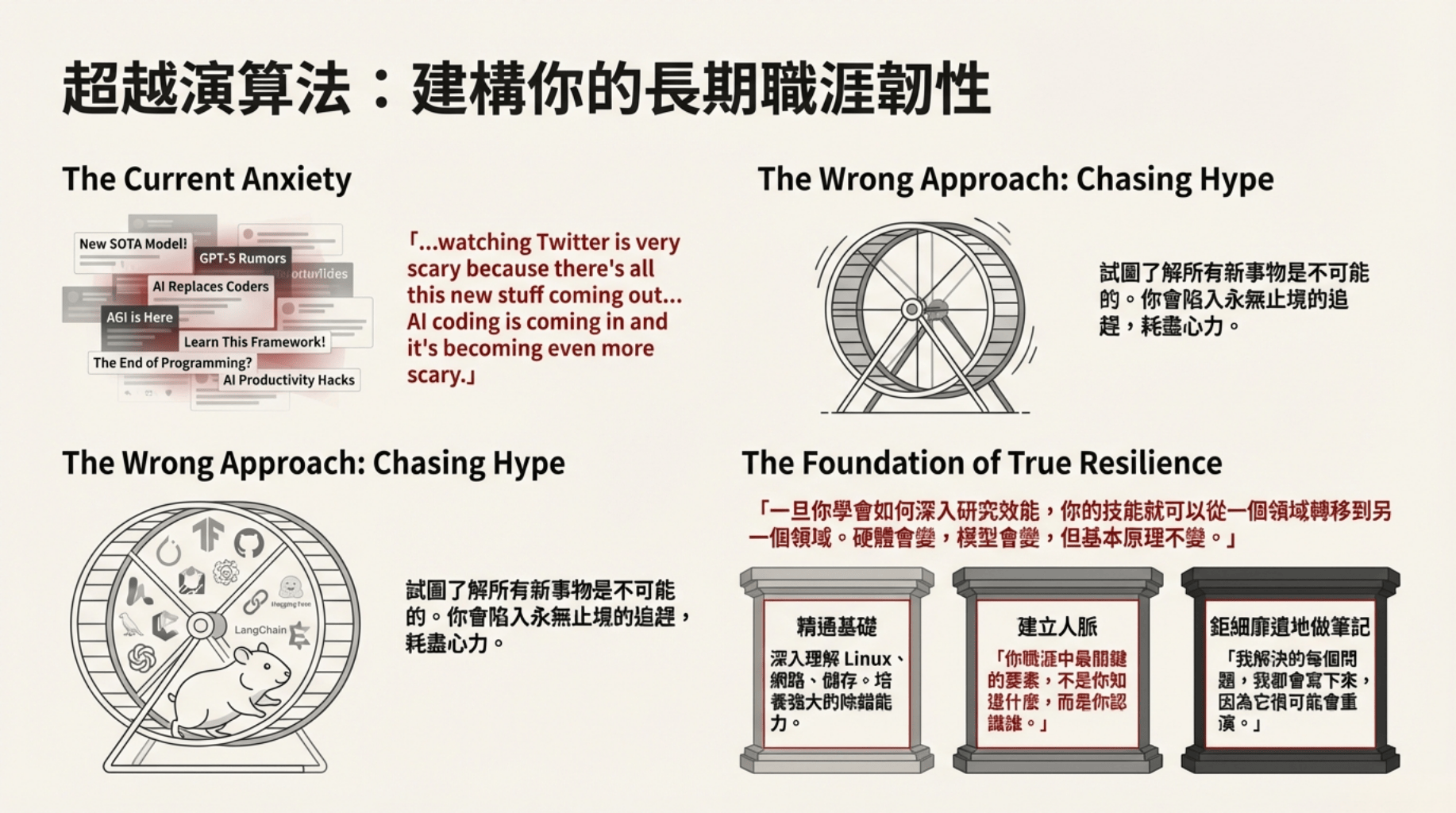
與其在社交媒體上追逐 24 小時後就消失的熱度,不如建立長期的知識沉澱。
• 宗教式地做筆記: Stas 將解決過的每一個問題、測試過的每一個基準都寫成開源書籍(如《ML Engineering Open Book》與《The Art of Debugging》)。
• 建立專業標籤: 這些筆記不僅是他日常工作的字典,更是向未來的雇主展現你「如何思考」的最佳證明。
結語:如何在 AI 自動化浪潮中生存?

AI 可以進行模式匹配(Pattern Matching),但目前還無法像人類一樣進行深度邏輯思考與處理複雜的系統工程。
• 策略: 尋找你熱愛的利基領域,嚴謹地記錄經驗,並持續為開源社群提供價值。不要複製別人,要找到你自己的路。
YouTube Link: Lecture 90: Building resilient ML Engineering skills
Book Link: ML Engineering Open Book
Book Link: The Art of Debugging
作者:Thomas