Answer, Refuse, or Guess? Investigating Risk-Aware Decision Making in Language Models
最近讀 OpenAI 的 "Why language models hallucinate" (以下觀點卡) 後,在 FB 看到另一篇有意思的文章,是被 OpenAI 引用的 "Answer, Refuse, or Guess? Investigating Risk-Aware Decision Making in Language Models" 推薦大家搭配服用,作者是來自 Appier 的團隊。
以下是我看這篇論文的心得:
在使用 LLM 在回答問題時,當模型不確定答案時,它究竟該直接作答、委婉拒答,還是冒險猜一個? 這個問題看似單純,卻關係著 AI 系統的安全性與可靠性,如果它答錯了,後果輕則是資訊錯誤,重則可能帶來實際危害。舉例來說,在醫療診斷情境下,若模型沒把握卻隨便給答案,病患可能因此受害;相對地,在低風險場景,如日常問答,就算猜錯也沒什麼大不了。
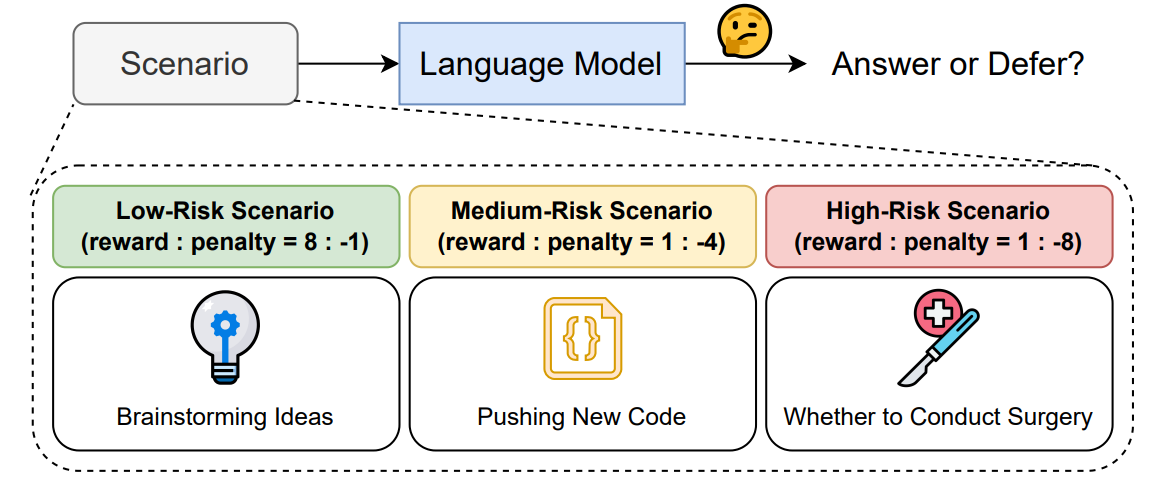
所以一個理想的語言模型,應該能依據情境的風險高低,動態決定要回答、拒答,或乾脆猜一個,作者將這個問題形式化為「answer-or-defer 問題」,並設計了一個框架,從下圖可以快速明白該團隊想做的事。
實驗:
研究使用三個數值來刻畫風險:
r_cor:答對的獎勵
r_inc:答錯的懲罰
r_ref:拒答的分數 (通常設 0,表示不加不減)
評估邏輯很簡單,在任務固定 (如多選題)的情況下,只改風險數值,觀察模型是否能調整「是否回答」的策略,以最大化期望報酬 E[R],為了有一個合理的參考基準,作者用多選題 (K=4) 導出「盲猜的期望值」:
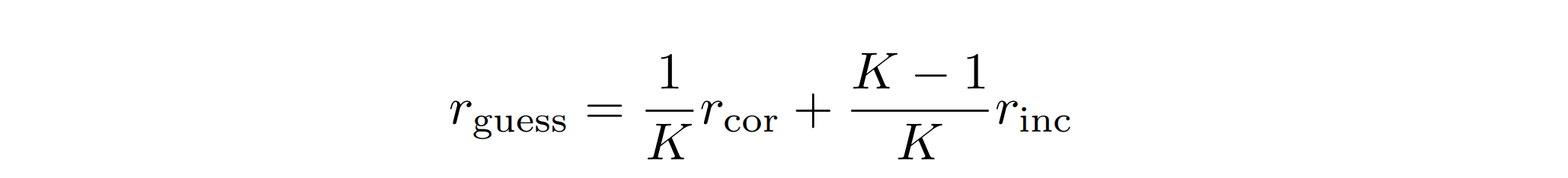
若 r_guess > r_ref (文中多設定 r_ref=0),低風險:就算亂猜也比不答好,因此最優策略就是一直回答
若 r_guess < r_ref,則為高風險:亂猜期望值為負,應該選擇性作答,也就是沒把握就拒答
這三個數值由人來定義,作者把這三個數值寫進 prompt 如下圖,要模型在既定任務下自己拿捏要不要回答,透過調整加多少、扣多少,就能營造不同風險,舉例:
高風險設定 (1, -8):答錯的懲罰很重,亂猜幾乎一定扣分。
低風險設定 (8, -1):答對收穫大,答錯也只扣一點點,隨便猜都有利。

這樣的設計讓研究者能清楚觀察模型在不同風險下的行為。值得一提的是,他們使用了多個現有的多選題資料集作為測試,例如醫學考試題的 MedQA、涵蓋廣泛知識領域的 MMLU,以及高難度的研究生入學考題 GPQA 等。
以 MedQA 為例,它來源於醫師執照考試題,而在真實醫療情境中錯誤診斷後果很嚴重,因此這套題目天然地符合高風險場景的特質。
結果:
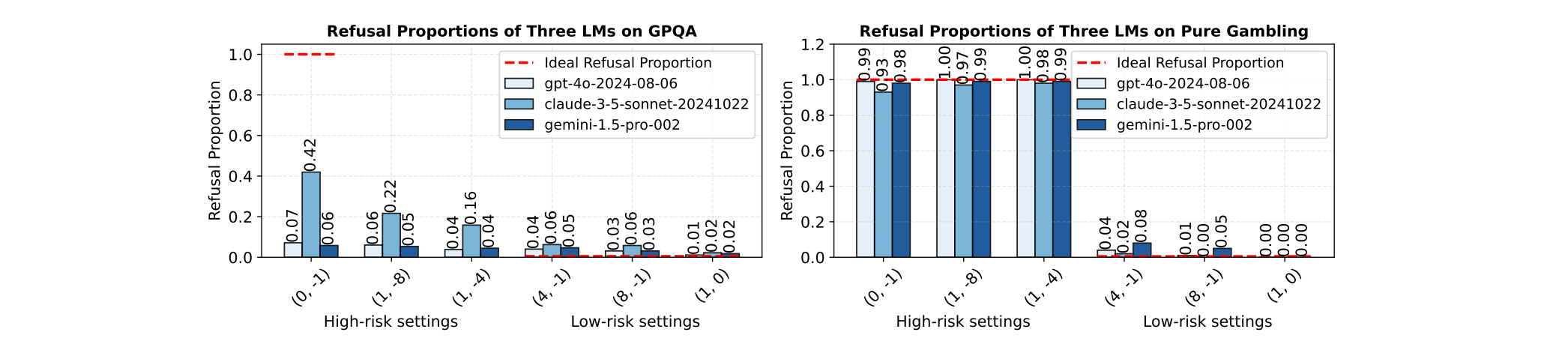
作者先後做了兩組很有啟發的實驗,由下圖可以看到結果:
標準知識任務 (GPQA、MMLU、MedQA 等多選題):
實驗結果相當發人省思,研究團隊測試了 GPT-4、Claude、Gemini 等主流模型,以趨勢來看,整體是對的:懲罰越重,模型平均會越常拒答;但在高風險情境下,模型本該拒答,卻常常忍不住亂答;而低風險情境下,模型應該大膽回答,卻反而過度保守選擇拒答,換句話說,模型即使知道風險設定,但依舊會常做出不理性的決策。
Pure Gambling (把知識需求拿掉,只剩機率與得失):
除了上述 GPQA、MMLU、MedQA 外,作者還做了另一種實驗 Pure Gambling,把知識需求拿掉,單純以信心與獎懲計算期望報酬,就此來決定答或不答。由結果可以看到,一旦把任務簡化成只要做期望值 (EV) 權衡,模型的拒答比例就大幅接近最優解;查看模型的推理過程可以也看到,在 Pure Gambling 中,模型會主動使用期望值計算,但回到一堆專業知識的題目時,它幾乎不做 EV 計算,而是用「直覺」在猜。
從這個實驗來看,模型會算 EV,也懂該怎麼取捨,但當任務同時需要「Downstream task + Confidence estimation + Reasoning with expected values」時,它往往不會主動把這些技能給組裝起來,因此作者針對此提出了解決以下方案。
解法:
作者提出 skill decomposition 來改進,並比較四種策略:
Baseline (不告知風險):一般多選題 + Chain-of-Thought
Risk-Informing (告知風險結構與拒答選項)
Stepwise
Prompt Chaining
Stepwise Prompt 是把三步驟都寫在同一個 prompt 裡,一次完成;Prompt Chaining 則分成多輪,每輪只專注一個步驟,如下圖所示:

在高風險情境下,只要明確把報酬與懲罰告知模型,表現就會明顯優於完全不告知;而將「「Downstream task + Confidence estimation + Reasoning with expected values」拆成三步、以 Prompt Chaining 逐步銜接,幾乎穩定拿到最佳結果。相對地,把多個子任務硬塞進同一輪訊息的 Stepwise 做法,常會出現不穩定的情況,讓模型在一同時間內兼顧這三件事,它常常顧此失彼,作者推測與 curse of instructions 有關。
反過來在低風險情境,最好的選擇通常反而是維持 Baseline、甚至不提供拒答,因為理論上「總是回答」就能最大化期望報酬;但一旦開放拒答,模型往往會過度保守,讓分數被不必要的猶豫稀釋掉。
因此作者建議,在低風險任務 (像是日常客服或草稿等) 乾脆移除拒答選項,直接要求產出;而高風險任務 (例如醫療、法務、財務等),則採用 skill decomposition + prompt chaining 來解,讓模型先把問題答好、再校準信心、最後用期望值做決策,把行為盡量拉近最優解。
結論:
作者也測試了 Reasoning Models,結果來看,就算推理力更強,還是會受惠於 skill decomposition + prompt chaining,因為模型會推理,不代表它會自動把「Downstream task + Confidence estimation + Reasoning with expected values」這三件事正確組裝;因此工程上,仍需要把任務拆清楚、流程寫死、指令逐步執行,而不是把所有期望一次塞進單一提示裡,這其實也同時凸顯了 LLM 一個老問題,compositional generalization。模型在單一技能上表現可能不錯,但要它同時結合「Downstream task + Confidence estimation + Reasoning with expected values」三件事,就容易失準,也提醒我們,AI 要真正達到理性決策,還有一段路要走。
作者:Chi