Twinkle AI:從零開始到實戰-預訓練與應用心得分享
講者:黃亮勳 | Twinkle AI | Founder
活動:11/30 DevFest Taipei 2025
題目:從零開始到實戰預訓練與應用心得分享
上週末參加了 GDG 主辦的 DevFest Taipei 2025 活動,聽到 Twinkle AI 的亮勳分享「從零開始到實戰:預訓練與應用心得分享」,收穫滿滿,趕緊分享給大家,講者一路從 為什麼還有人要自己訓練模型 講到 如何從零打造一個繁中小模型,中間踩到的坑、調資料的方法、成本估算等,各種眉眉角角都講得非常直白。
對正在做本地化模型、RAG、或需要模型 customization 的人,這場真的很值得看一下。

一、為什麼還要自己訓練落地模型?
講者一開頭用這句話直接破題,畢竟在大型雲端模型(如 Gemini 或 GPT)日益強大的今天,為什麼企業或社群仍需要自己訓練和微調模型呢? 主要是因為以下三個原因:
1. 隱私性 (Privacy):在金融或國防工業等特殊領域,政策通常不允許將敏感資料丟上雲端。
2. 領域專精 (Domain):如果你的應用領域過於專業或在地化,雲端模型(訓練數據可能來自網路爬蟲)回答的內容往往「不夠對味」。
3. 成本考量 (Cost):當模型的使用量或查詢量變大時,持續使用雲端模型的成本會變得非常昂貴,訓練一個可落地的微調模型是必要的解決方案。
Gemini 3 很強沒錯,但這不代表大家的需求都能直接被滿足,接下來我們就跟著講者的腳步,來看看如還從 0 到 1 打造一個專屬自己的地端模型。
二、範例模型:Gemma 3
Google 在今年初推出了 Gemma 3 系列模型,Gemma 在希臘文中有「珍貴的寶石」之意(講者介紹之前我都不知道XD),這系列模型採用了與 Gemini 相同的技術訓練而成,主要可以分為幾種:
• Gemma 3: 處理文字或視覺模態的輸入,輸出文字。
• Gemma 3n: N代表多模態。
• MedGemma: 偏向醫學相關領域的模型。
• EmbeddingGemma: 向量嵌入模型。
這次案例主角是 Gemma-3-270m,屬於文字模態輸入/輸出的模型,也是一個小到不可思議的模型,可以對比以前的 Bert 與 ChatGPT-2 的大小來想像。官方手冊上這個模型擁有 128K 的 Context Size,支援超過 140 種語言,非常適合部署在資源受限的終端裝置如手機上,光看規格覺得非常棒,但這樣的模型在繁體中文表現上究竟如何呢?
經講者測試後發現,當使用繁體中文問 Gemma-3-270m 時,模型經常預設用簡體中文來回答;除此之外,由於 270M 的參數量相對較小,模型回答的內容通常也較簡短,知識量有限。因此,這次實戰的目標就是為了大幅加強它處理繁體中文的能力。
三、建資料集:打造 FineWeb-Edu-zhtw
為了讓模型真正學會高品質的繁體中文,光有大量資料不夠,資料的乾淨程度、品質等才是關鍵,但 Hugging Face 的繁中資料很多都是垃圾,不能直接拿來預訓練,這是所有做繁中模型的人都知道的痛。近期他們借鏡 FineWeb 與 FineWeb-Edu 的做法,FineWeb 是近年 Hugging Face 整理出的廣乏大型網路語料,包含各國語系,但是文本品質不一;而 FineWeb-Edu 更進一步,只保留「教科書等級」的內容,品質高到足以用來訓練模型的基礎語言能力。
因此為了從 FineWeb-zhtw 中挑選出高品質的教育內容,他們想要打造一套 繁中 classifier,去把大量網路文本裡的「教科書等級內容」挑出來製作成 FineWeb-Edu-zhtw 訓練集,從下圖就能很明顯地看到,要達到這個目的有兩階段的工作需要做。
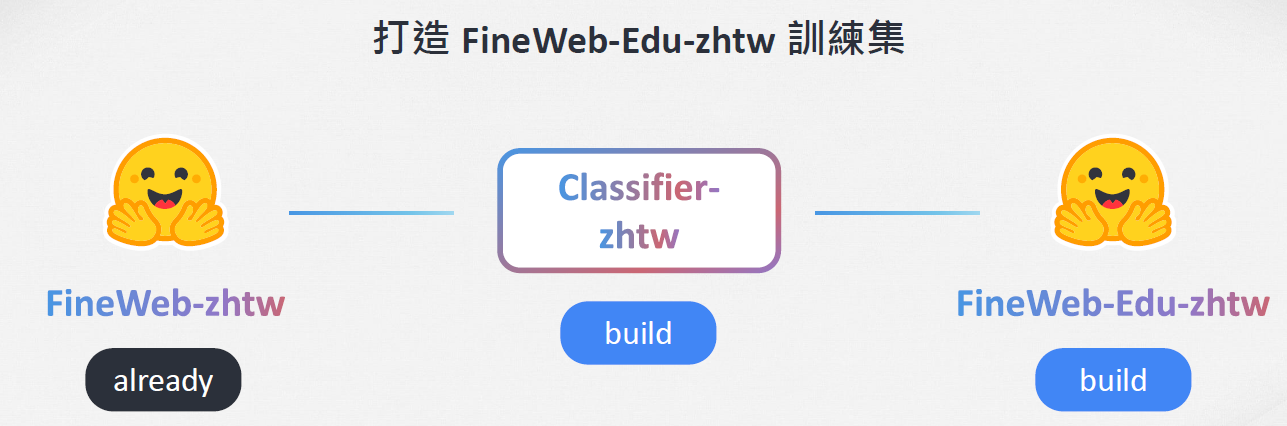
1. 訓練 Classifier-zhtw
這個 Classifier 是他們自己標資料與訓練模型,一路磨出來的。
使用工具: 他們利用 embeddinggemma-300m 作為基礎,疊加一個 classification head 來構築這個分類器。
標註資料: 透過與台灣大哥大合作,並結合 Twinkle AI 社群夥伴提供的優秀 Prompt,他們使用了Magistral-Small-2506 去對文本進行 0 到 3 分的教育價值評分,最終累積了 500 萬筆的 annotations。
2. Fineweb-Edu-zhtw
最後使用上面的 Classifier-zhtw 篩選出繁體中文首個「教科書等級文本」,包含了大約 200 萬筆樣本、約 20 億 (2B) Tokens 的高品質資料,目前也已經開源。
如此一來,資料集就準備好了,接下來馬上看到怎麼樣做 Pre-training。
四、模型 Pre-training
在前一段我們把繁體中文資料集完整準備好之後,接下來的問題就是,模型到底要怎麼把這些新知識「吃進去」?
這是今天最核心也是最容易被忽略的環節:Pre-training(預訓練)。
很多人以為有資料就餵下去就會學會,但講者提到他的經驗完全不是這樣,小模型像 Gemma-3-270m 其實非常脆弱,學習率、語料比例、token 數任何一個配錯,都會讓模型不是忘記原本的能力,就是根本洗不起來。
這部分有許多坑與技術,但講者很貼心的幫新的幫大家整理了幾個關鍵點:
ChinChill’s law:小模型需要的 token 量其實比想像中來的多,
270M 的模型大概要 4B tokens 才能有效更新語言能力。
調和比例: 為了避免災難性遺忘(模型忘記原本學會的知識,如小孩被丟去美國回來不會講國語一樣),訓練前必須混合一定比例的原文本,這邊採用 1:1 的中英比例。
訓練細節與經驗: 訓練環境使用了 8 顆 B200 GPU,講者特別強調,對於小參數量的模型,Learning Rate 是關鍵,如果設定太小,知識會「洗不上去」,建議朝 10 的負 4 次方這個方向去調整。
訓練參數參考:
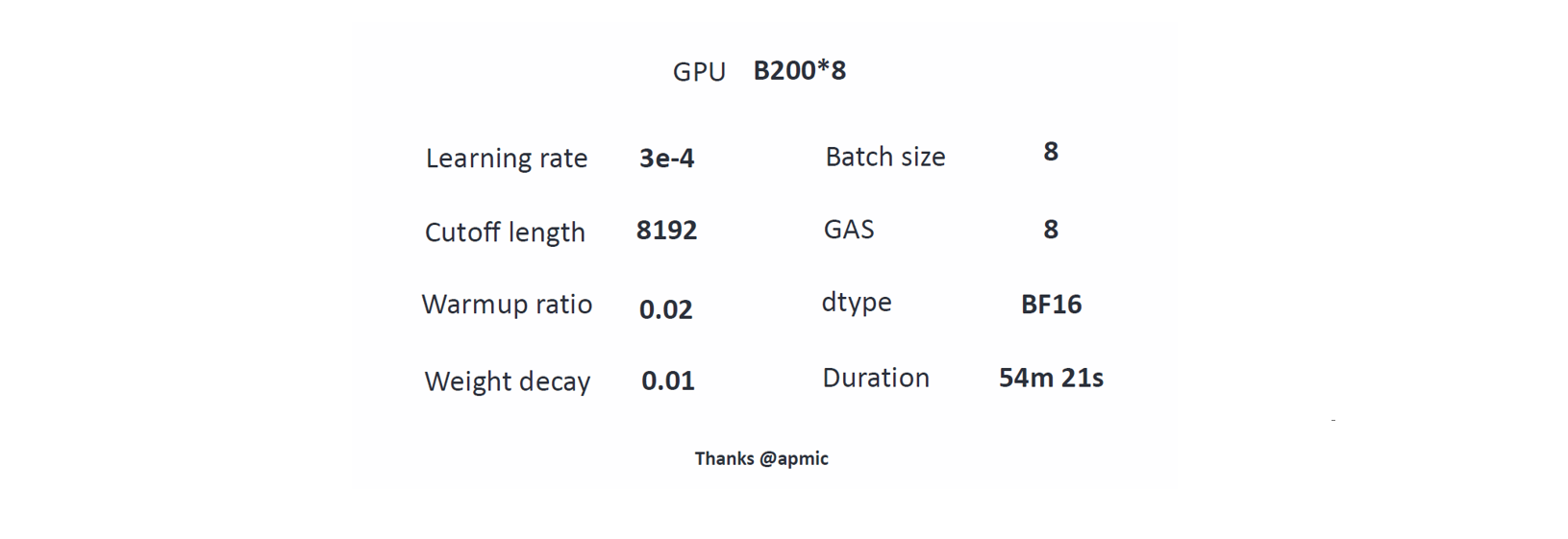
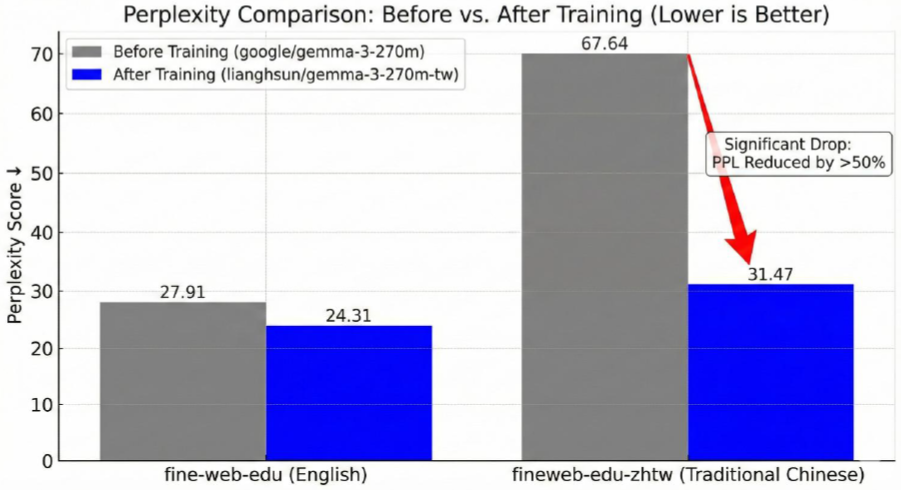
訓練後的模型命名為 gemma-3-tw-270m,通過困惑度 (Perplexity Score, PPL,越低越好) 評測,模型在處理繁體中文文本時,PPL 顯著下降,降幅超過 50%,證明繁體中文能力確實大幅提升,這模型也都有開源。
四、模型 Post-training/SFT
在 Pre-training 之後,模型已經具備基本語言能力,但這還不算真正能用,對話式 AI 要能回答問題、遵守格式、理解任務意圖,這些都不是預訓練會自動學會的,因此接下來的 Post-training / SFT(Supervised Fine-tuning) 就成了小模型能不能落地的關鍵,講者在這段的做法與觀察如下:
使用 tw-instruct-500k 作為 SFT 數據
講者使用了先前整理好的 tw-instruct-500k 對話資料集來讓模型學習如何在人類的語境下合理互動。
SFT 的成敗關鍵仍然是 learning rate
小模型對超參數非常敏感,跟 Pre-training 一樣,在這裡 learning rate 還是關鍵所在,
調太高會炸掉,調太低模型會學不起來,因為小模型的 capacity 小,參數更新的節奏需要極精準。
調教後的台灣版模型,不僅能用繁體中文回覆,還能吐出具備知識量的高品質長文本;不過,由於參數量仍小,也就是所謂的腦容量有限的情況下,模型出現幻覺的現象依然存在。
五、應用範例
雖然 270M 的模型不適合當作通用模型,但它非常適合進行下游任務的微調應用,講者這邊提出了兩個超級好笑又實用的應用:
1. PTT 鍵盤俠回覆生成器 (Keyboard Warrior)
目標: 訓練模型使用 PTT/Dcard 的嗆辣、幽默、愛用網路梗的口吻進行回覆。
資料集生成: 利用 Gemini 2.5 Flash 進行 Vibe Coding,利用 LLM 寫 Prompt 來自動生成資料集,僅用 10 分鐘就產出了 3,000 多筆高品質的聊天樣本,也有開源在 tw-ptt-keyboard-warrior-chat
成果: 訓練出的模型確實能用鍵盤俠的口吻回覆,非常適合各大鄉民。
2. 唐伯虎詩詞生成器 (Poetry Generator)
目標: 訓練模型將現代文輸入轉化為押韻且工整的七言絕句。
資料集生成: 同樣使用 Gemini 2.5 Flash 產生了 7,000 多筆七言絕句樣本,開源在 tw-poetry-chat
成果: 模型能夠成功地進行這種文體轉化,很有意思
講者透露,針對特定的下游小任務,只要資料量達到 1K 筆左右,模型的訓練效果就會開始顯現,如果各位被老闆問到,可以用此為依據。
六、結語
這次的實戰證明了即使是小參數量的模型,只要透過高品質的預訓練資料和精準的微調,也能夠將其繁體中文能力大幅提升,並在特定應用場景中發揮巨大作用,從頭到尾最打動我的一句話:
「模型有缺陷沒關係,下游任務已經夠用了。重要的是台灣要有人開始做。」
講者不是在畫一個壯闊的藍圖,而是展示一條只要耐心就做得到的道路,先把繁中文本整理乾淨,再建 classifier,然後一段一段把模型的語感、常識、語法補回去,這聽起來又累又不帥,但這正是語言模型的基礎建設。
尤其是看到一個 270M 的小模型,被這樣訓一訓後竟然可以寫詩、講鄉民語氣、也能聽懂繁中長文本,會突然有種 "這好像真的不是遙不可及" 的感覺,非常佩服。
如果說今年大家都在追 GenAI 應用或講 AI 如何商業化,這場分享更像在提醒我們一件更根本的事,要想繁體中文在 AI 時代站得住腳,就得有人從最底層開始打地基。不是喊口號,不是等大公司給資源,而是有人願意從語料開始,把地基一塊一塊鋪起來。
這場演講我覺得最有價值的不是 demo,而是讓大家看到,那塊地基是怎麼被慢慢被鋪出來的,以及我們怎麼一起加入把它做得更好,非常歡迎有興趣與熱情的夥伴一同參與。
Twinkle AI Discord: 連結
作者:Chi