我把 Mitchell Hashimoto 的 harness engineering 想法,整理成 repo-level 的 6 個元素

大家好,我是來自韓國的初級開發者。
繁體中文是用工具輔助寫的,如果有不自然的地方請見諒。
最近我在 dogfood 一個開源專案:
https://github.com/baskduf/harness-starter-kit
之前我分享過一次,用一個真實 PR 來記錄 AI coding agent 的 task outcome。
那篇文章裡,我提到自己還不能說:
harness 已經證明讓 agent 更有效。
因為目前還沒有足夠 baseline,也沒有足夠多的 task outcome records。
這次我想補充的是,這個專案背後更核心的一個想法來源。
受到 Mitchell Hashimoto 的啟發
Mitchell Hashimoto 在這篇文章裡寫到他的 AI adoption journey:
https://mitchellh.com/writing/my-ai-adoption-journey
其中我最有感的是 Step 5: Engineer the Harness。
我理解他的意思大概是:
當 coding agent 做錯事時,不只是這次把它修好,而是要改善 harness,讓 agent 下次比較不容易犯同樣的錯。
例如:
agent 常常跑錯 command,就把正確 command 寫進
AGENTS.mdagent 常常找錯 API,就補充專案規則
agent 常常改到不該改的地方,就加檢查或 review rule
agent 需要確認 UI 或測試結果,就提供更快的 verification tool
這個想法對我很有說服力。
因為我自己使用 Cursor / Claude Code / Codex 時,也常常遇到類似問題:
每次新 session 都要重新說明專案規則
agent 忘記跑測試
agent 修改不該修改的 generated file
agent 重複以前已經踩過的錯
修完一次之後,下次 session 又忘記
所以我開始想:
如果把 harness engineering 放到 repository 層級,會長什麼樣子?
我目前整理成 6 個元素
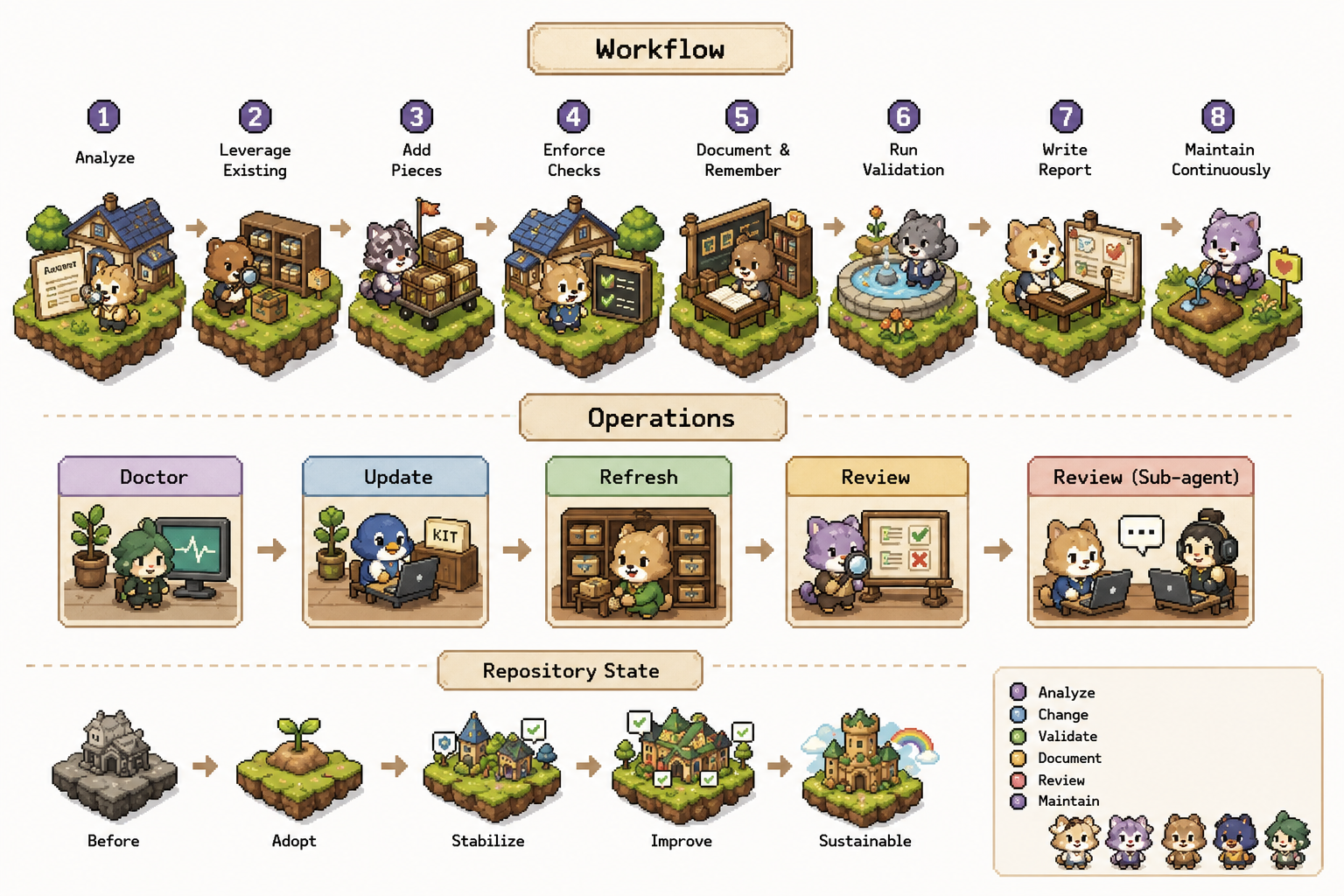
我現在把 repo-level harness 暫時整理成 6 個元素:
Harness = Instructions + Constraints + Feedback + Memory + Evaluation + Governance
這不是成熟理論,也不是我想發明一個新名詞。
比較準確地說,這是我目前 dogfood 時用來檢查 repository 是否適合 coding agent 工作的工作模型。
1. Instructions
第一個元素是 Instructions。
也就是讓 agent 知道這個 repo 的基本規則。
例如:
專案用什麼 package manager
測試 command 是什麼
哪些目錄不能改
generated files 不要手動修改
secrets / credentials 不要印出或 commit
PR 前需要跑哪些檢查
常見的檔案可能是:
AGENTS.md
CLAUDE.md
.cursor/rules
.github/copilot-instructions.md
以前這些規則常常只存在聊天紀錄裡。
但聊天紀錄很容易消失,也很難被下一個 session 繼承。
所以第一步很簡單:
把最常重複講給 agent 的規則,放進 repo。
2. Constraints
第二個元素是 Constraints。
只有文件還不夠。
如果某個規則可以被機器檢查,就應該盡量變成 check。
例如:
lint rule
type check
import boundary check
forbidden path check
docs drift check
generated file hygiene check
CI gate
比起只寫:
不要從 routes 直接 import database module
如果可以用 lint 或 script 擋住,效果會更穩。
我的想法是:
重要規則不要只靠 agent 自律。能檢查就檢查。
3. Feedback
第三個元素是 Feedback。
agent 改完東西之後,需要快速知道自己錯在哪裡。
這裡包括:
unit tests
focused tests
smoke checks
build command
typecheck
browser verification
CI result
這點很重要,因為 agent 不是只需要 instruction。
它也需要一個快速回饋迴路。
如果 feedback 太慢、太模糊、太依賴人工,agent 很容易在錯的方向上繼續改。
所以我會把 normal gate 和 focused/manual gate 分開。
例如:
deterministic local test 可以放進 normal gate
需要 credentials、quota、live API 的 smoke check 不一定適合每次都跑
外部 API 測試要清楚標記為 manual 或 focused
4. Memory
第四個元素是 Memory。
這是我覺得 repo-level harness 最重要的部分之一。
很多 agent mistake 不是第一次發生。
只是上一次的教訓留在聊天紀錄裡,repo 本身沒有記住。
所以我現在會把重要記憶放進 repo,例如:
docs/decisions/
docs/failures/
docs/conventions/
docs/domain/
docs/decisions/ 用來記錄重要決策。docs/failures/ 用來記錄不想再犯的錯。
但 failure memory 不能只是寫:
之前這裡壞過,要小心。
更好的 failure note 應該說清楚:
發生了什麼
為什麼重要
下次怎麼偵測
哪個 test / check / manual review point 可以避免重複
也就是說:
failure memory 要連到 detection 或 prevention。
不然它只是文件,不是 harness。
5. Evaluation
第五個元素是 Evaluation。
這是我最近特別小心的地方。
repo 裡有 AGENTS.md、checks、failure notes,不代表 agent 真的變有效。
這只能說 harness health 比較完整。
但 agent effectiveness 是另一回事。
我現在會分成兩層:
Harness health:
repo 裡有沒有 durable rules / checks / memory?
Agent effectiveness:
真實 task 裡,agent 是否更少越界、更少重複錯誤、更少需要 human rework?
所以我不想只說:
這個 repo 有 harness,所以 agent 變強了。
我更想記錄:
expected file boundary 是什麼
actual changed files 是什麼
wrong-file edit 有沒有發生
repeated known mistake 有沒有發生
first-pass verification 有沒有通過
human rework 花了多少時間
這次 outcome 能不能和下次比較
這就是我目前在試的 task outcome record。
6. Governance
第六個元素是 Governance。
這聽起來有點重,但其實很實際。
如果 repo 裡開始有 rules、checks、failure memory、decision records,接下來一定會遇到問題:
規則過期了怎麼辦?
docs 重複了怎麼辦?
checks 和實際專案不一致怎麼辦?
starter kit 更新了,target repo 要不要跟?
agent 會不會盲目覆蓋既有檔案?
所以 harness 也需要維護流程。
在我的 kit 裡,目前有幾個 prompt-level command:
/harness doctor
/harness update
/harness refresh
/harness review
它們不是神奇 command。
比較像是給 agent 的 workflow 約定。
例如:
/harness doctor只診斷,不修改檔案/harness update更新 starter kit reference,但不能盲目覆蓋 target repo/harness refresh檢查 stale / duplicated guidance/harness review從反方角度檢查目前 change set
我的原則是:
harness 不能變成另一個失控的自動化來源。
它應該幫 repo 更穩定,而不是讓 repo 多一堆沒人維護的文件。
目前還在測試中
我想特別強調:這還在測試中。
我目前只能比較負責任地說:
這個 kit 讓我開始把 coding agent 的規則、檢查、失敗記憶和 task outcome 放進 repo,而不是只留在聊天紀錄裡。
但我還不能說:
它已經證明降低了 agent mistake。
要證明這件事,還需要更多資料,例如:
pre-harness baseline
更多 PR
更多 comparable product tasks
human rework minutes
prompt reference / prompt hash
repeated known mistake 的長期追蹤
所以目前我把它當成一個 repo-level experiment。
不是 agent magic。
也不是 installer。
比較像是一個 feedback loop:
agent 犯錯
repo 記住
repo 加規則或檢查
下次更早發現
再把 harness 修好
我想請教大家
想請教台灣開發者幾個問題:
你們使用 Cursor / Claude Code / Codex 時,會把專案規則放在哪裡?
AGENTS.md這類 repo-local instruction 對團隊有幫助嗎?你們覺得 failure memory 應該寫進 repo,還是留在 issue / PR / chat 就好?
如果要衡量 AI coding agent 是否真的有效,你們會看什麼指標?
這種 repo-level harness 會不會太重?
專案連結:
https://github.com/baskduf/harness-starter-kit
我還是初級開發者,所以這個方向還在摸索。
如果這個想法有問題,或有更好的做法,歡迎直接批評。
作者:Yuan